


In diesen Artikeln wollen wir das Thema der partitionierten Tabellen ein wenig differenzierter betrachten. Dabei stehen die Fragen „Wann sollten partitionierte Tabellen verwendet werden?“ und „Welche Aspekte spielen für das Design eine Rolle?“ im Vordergrund.
Voraussetzung, um mit partitionierten Tabellen zu arbeiten, ist das Lizenzprogramm DB2 Multisystem (5770SS1 Option 27). Falls Sie sich jetzt fragen, was partitionierte Tabellen sind, ist die Antwort eigentlich sehr einfach:
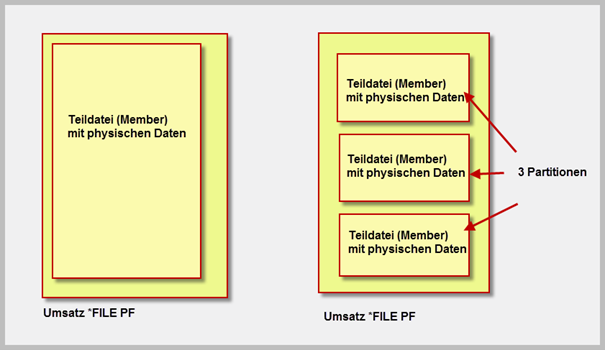
Partitionierte Tabellen sind „moderne“ Multimember-Dateien, die wir bereits aus vergangenen Zeiten kennen. Der entscheidende Unterschied ist allerdings im Handling zu sehen. Mussten die einzelnen Member einer physischen Multimember-Datei früher mit Hilfe von logischen Dateien angesprochen werden, verhält sich die partitionierte Tabelle wie ein Objekt. Sie müssen also beim SELECT, INSERT, UPDATE oder DELETE nicht wissen, in welchem Member die Daten liegen!
 Quelle: Rasche
Quelle: RascheAllerdings müssen Sie bei partitionierten Tabellen einige Restriktionen in Kauf nehmen:
- Vor Release i7.1 waren referenzielle Integritätsbedingungen und
Autoinkrement-Spalten in partitionierten Tabellen nicht erlaubt. - Vor Release i7.2 konnte der Partitionsschlüssel nicht durch Updates manipuliert werden. Um den Partitionsschlüssel eines Satzes zu verändern, musste die Zeile gelöscht und neu eingefügt werden. Eine vollständige Liste der Restriktionen finden Sie im IBM i Knowledge Center unter folgendem Link:
https://www.ibm.com/support/knowledgecenter/ssw_ibm_i_73/dbmult/partrestrict.htm
Außerdem müssen Sie ggf. einige CL-Programme und Befehle anpassen und zukünftig die Option MEMBER *ALL verwenden. Dies gilt beispielsweise für Programme, die mit folgenden CL-Commands arbeiten:
- Clear Physical File Member (CLRPFM)
- Copy from Importfile – CPYFRMIMPF
- Copy to Importfile – CPYTOIMPF
- Open Query File – OPNQRYF
- Run Query – RUNQRY
- Work with Object Locks – WRKOBJLCK
- Apply Jpurnal Changes – APYJRNCHG
- Display Journal – DSPJRN
- Receive Journal Entrys – RCVJRNE
- Removed Journal Changes – RMVJRNCHG
- Retrieve Journal Entrys – RTVJRNE
- Restore Object – RSTOBJ
- Save Object – SAVOBJ
- Save restore Object – SAVRSTOBJ
und einige mehr.
Wofür werden partitionierte Tabellen benötigt?
Wann und warum werden partitionierte Tabellen wichtig? In relationalen Datenbanksystemen ist es häufig notwendig mit partitionierten Tabellen zu arbeiten, wenn für die Datenverarbeitung parallele Prozesse genutzt werden sollen. Dies ist auf einem IBM i Server allerdings nicht der Fall. Ihr Server kann parallele Verarbeitungsmethoden nutzen, egal ob die Tabellen partitioniert oder nicht partitioniert sind. Entscheidend für die Parallelverarbeitung auf einem IBM i Server ist das Feature DB2 Symmetric Multiprozessing (5770SS1 Option 26).
Wofür also benötigen wir dann partitionierte Tabellen? Für die Massendatenverarbeitung! Wenn Sie das Größenlimit einer Datei erreichen und das Datenbankdesign nicht ändern wollen oder können, kann das Problem mit Hilfe partitionierter Tabellen gelöst werden. Für nicht partitionierte Tabellen existiert ein Größenlimit für die Zeilenanzahl und für die Gesamtgröße einer Tabelle. Welche Limits existieren, zeigt die nachfolgende Tabelle.
| Satzlänge (Byte) | Anzahl der Zeilen |
| 32766 | 57 Millionen |
| 8192 | 228 Millionen |
| 2048 | 912 Millionen |
| 1024 | 1,8 Milliarden |
Da in einer partitionierten Tabelle bis zu 256 Member liegen können, ist es mit partitionierten Tabellen möglich 256 mal 57 Millionen Sätze à 32766 Byte zu speichern. Theoretisch können Sie also bis zu 435 TB an Daten in einer Tabelle speichern.
Effizientere Massendatenverarbeitung kann eventuell auch ein Grund für die Einführung von partitionierten Tabellen sein. Stellen Sie sich vor, es gibt eine Umsatzdatei, in der die Daten mehrerer Jahre verwaltet werden. Schnell können hier Millionen von Datensätzen entstehen und im „Online Transaction Processing (OLTP) “ können sich die Antwortzeiten mit der Zeit deutlich verschlechtern. In den meisten Fällen werden Sie vermutlich auf die aktuellen Umsatzdaten des laufenden Jahres zugreifen müssen. Hier könnte es sinnvoll sein, die Umsatztabelle anhand des Auftragsdatums zu partitionieren. Sie haben hier zwei Vorteile:
- Es muss ggf. nur noch das Member mit den aktuellen Umsatzdaten gesichert werden. Die Datensicherung wird auf diese Weise schneller.
- Vielleicht wollen Sie die Umsatzdaten auch nur drei Jahre auf dem Server vorhalten und ältere Daten stets archivieren? Auch dieser Prozess ist einfach, da sie das entsprechende Member nach der Archivierung einfach löschen können. Insbesondere in Hochverfügbarkeitsumgebungen kann dieses Vorgehen Vorteile haben, denn es müssen nicht mehr tausende von Löschoperationen gespiegelt werden, sondern lediglich eine Löschanweisung für die entsprechende Partition ausgegeben werden.
- Damit aber auch Ihre Datenbankzugriffe weiterhin effizient sind, ist es bei einem solchen Szenario wichtig, dass das Auftragsdatum Primärschlüssel der Datei wird und in den SQL-Zugriffen stets das Datum als lokales Selektionskriterium verwendet wird, damit der Optimizer sich auf eine Partition beim Datenzugriff fokussieren kann.
Auch ein anderes Szenario könnte von partitionierten Tabellen profitieren. Stellen Sie sich vor, dass nachts regelmäßig neue Daten in eine Tabelle übernommen werden. Nur die neuen Daten müssen anschließend weiterverarbeitet werden. Anstatt anhand eines
Timestamp-Felds die neuen Datensätze zu lokalisieren, könnten auch partitionierte Tabellen eingesetzt werden. Jede Nacht werden die Daten in einer neuen Partition übernommen und anschließend wird lediglich diese Partition weiterverarbeitet.
Prüfen Sie vorher aber stets genau, ob die Vorteile tatsächlich die Restriktionen und Nachteile aufwiegen. So wird beispielsweise die gesamte Tabelle exklusiv gesperrt, wenn ein Member gelöscht wird. Während dieser Zeit könnte sich der Zugriff auf die Tabelle deutlich verlangsamen. Bedenken Sie auch, dass Indizes, die nicht partitioniert sind, neu aufgebaut werden, wenn eine Partition der Tabelle hinzugefügt wird oder wenn Sie ein Member in der Tabelle löschen.
Wie werden partitionierte Tabellen erstellt?
Partitionierte Tabellen können Sie nur mit SQL erstellen. Im DDS gibt es dazu keine Möglichkeiten! Grundsätzlich unterscheidet man bei der Partitionierung zwei Verfahren:
- Systemdefinierte Partitionen mittels Hash-Algorithmus
- Benutzerdefinierte Partitionen anhand von Schlüsselwerten
CREATE OR REPLACE TABLE KUMULIERTER_UMSATZ FOR SYSTEM NAME KUMUMS
(
ID BIGINT,
JAHR SMALLINT,
QUARTAL SMALLINT,
MONAT SMALLINT,
FILIALE CHAR(5),
ERLOESE DEC(22, 2),
KOSTEN DEC(22, 2),
GEWINN DEC(22, 2)
)
PARTITION BY HASH(ID) INTO 5 PARTITIONS;Bei der Hash-Partitionierung geben Sie lediglich die Anzahl der Partitionen an. Anschließend verteilt das DBMS mit Hilfe eines Hash-Algorithmus die Daten eigenständig auf die verschiedenen Partitionen.
Es ist aber auch möglich, selbst Bereiche für die Partitionen vorzugeben:
CREATE OR REPLACE TABLE KUMULIERTER_UMSATZ FOR SYSTEM NAME KUMUMS
(ID BIGINT,
JAHR SMALLINT,
QUARTAL SMALLINT,
MONAT SMALLINT,
FILIALE CHAR(5),
ERLOESE DEC(22, 2),
KOSTEN DEC(22, 2),
GEWINN DEC(22, 2)
)
PARTITION BY RANGE(JAHR NULLS FIRST)
(STARTING FROM (MINVALUE) ENDING AT (2013) INCLUSIVE,
STARTING FROM (2014) ENDING AT (2014) INCLUSIVE,
STARTING FROM (2015) ENDING AT (2015) INCLUSIVE,
STARTING FROM (2016) ENDING AT (2016) INCLUSIVE,
STARTING FROM (2017) ENDING AT (2017) INCLUSIVE,
STARTING FROM (2018) ENDING AT (2018) INCLUSIVE,
STARTING FROM (2019) ENDING AT (MAXVALUE) INCLUSIVE
);In diesem Fall werden die Daten anhand eines „Schlüsselwerts“ auf die einzelnen Partitionen verteilt. Im Beispiel ist dies die Spalte JAHR. Der Partitionsschlüssel muss nicht explizit Schlüssel der Tabelle sein, aber Sie müssen darauf achten, dass die Daten den definierten Bereichen entsprechen, anderenfalls erhalten Sie eine Fehlermeldung:
 Quelle: Rasche
Quelle: RascheIn diesem Umfeld spielen ALIAS-Namen eine gewisse Rolle, mittels derer Programmierer eine Partition mit SQL direkt ansprechen können. Schauen Sie sich die folgende Abbildung an:
 Quelle: Rasche
Quelle: RascheMit Hilfe eines ALIAS-Namens können wir gezielt die einzelnen Partitionen ansprechen:
CREATE OR REPLACE ALIAS #2017 FOR KUMULIERTER_UMSATZ (PART000001);
CREATE OR REPLACE ALIAS #2016 FOR KUMULIERTER_UMSATZ (PART000002);
CREATE OR REPLACE ALIAS #2015 FOR KUMULIERTER_UMSATZ (PART000003);
SELECT ….
FROM #2017; Quelle: Rasche
Quelle: RascheAnmerkung: Sie erzeugen mit dem Befehl CREATE ALIAS ein Objekt der Art *FILE DDMF
Im RPG-Programm haben Sie verschiedene Möglichkeiten, ein spezifisches Member einer partitionierten Tabelle anzusprechen:
- Sie nutzen eine logische Datei, die für ein Member der Tabelle erzeugt wurde.
- Sie könnten auch den Alias-Namen verwenden. Allerdings muss der Alias-Name in diesem Fall zwingend auf den Systemnamen (Kurzname) der Tabelle verweisen.
- Seit einiger Zeit ist es im RPG-Programm möglich, mit den Schlüsselwörtern
EXTFILE(XXXX) und EXTMBR(PART00001) ein Member direkt anzusprechen.
Sollen mehrere Member im Programm verarbeitet werden, können Sie Variablen für die Definition verwenden. Sie müssen in diesen Fällen lediglich bedenken, dass Sie das Member schließen, bevor die nächste Teildatei geöffnet werden kann. - Natürlich können Sie auch den Befehl OVRDBF verwenden.
OVRDBF FILE(KUMUMS) TOFILE(UMSATZ) MEMBER(PART000001)
CALL RPG_PROGRAMMFalls es erforderlich ist, mittels RPG die gesamte Datei zu verarbeiten, brauchen Sie eine logische DDS-Datei oder einen nicht-partitionierten SQL-Index.
Bedenken Sie bei der Verarbeitung bitte, dass jede Partition eigene relative Satznummern hat, das heißt, die Partition 1 und die Partition 2 haben beide die relative Satznummer (RSN) 1. Eine Verarbeitung der Daten anhand der RSN ist somit schwierig.
Weiter geht es im nächsten TechKnowLetter.
Für 88 Euro gibt’s hier sechs Monate lang tiefgreifendes IBM i und SQL Wissen. Hier kann man abonnieren.