


Wer sich je schon einmal mit embedded SQL oder der Programmiersprache SQL auseinandergesetzt hat, wird auch schon einmal die Fehlermeldung „Indikator-Variable erforderlich“ erhalten haben. Normalerweise bedeutet diese Fehlermeldung, dass ein NULL-Wert ausgegeben wurde, der über eine Indikator-Variable geprüft werden kann. In diesem Artikel wird gezeigt, wie Indikator-Variable definiert und verwendet werden.
Was sind Indikator-Variablen
Bei der Ausführung von SQL-Statements, bei denen Daten zurückgegeben werden, erfolgt die Ausgabe in Host-Variablen. Sofern NULL-Werte ausgegeben werden, (was z.B. bei einem LEFT JOIN vorkommen kann, wenn in der zweiten Tabelle kein passender Satz gefunden wird), kann dies nicht in normale Host-Variablen erfolgen. In diesem Fall wird ein negativer SQLCODE (-305 = Indikatorvariable erforderlich) ausgegeben.
Über Indikator-Variablen werden zusätzliche Informationen zu dem ausgegebenen Ergebnis bzw. dem Inhalt der Host-Variablen ausgegeben:
- NULL-Wert
Wird ein NULL-Wert ausgegeben, wird die Indikator-Variable auf -1 gesetzt. Die Host-Variable bleibt unverändert, d.h. wird nicht initialisiert! Ohne Indikator-Variable wird die Ausführung des SQL-Statements mit Fehler, d.h. mit SQLCODE -305 (Indikator-Variable erforderlich) beendet.
- Data Mapping Error
Bei einem Daten-Konvertierungs-Fehler wird -2 in die Indikator-Variable ausgegeben.
- Ermitteln tatsächlicher Länge der alphanumerischen Daten.
Sofern ein alphanumerischer Wert bei dem Einlesen in eine Host-Variable abgeschnitten wird, wird die tatsächliche Länge des Strings in der Indikator-Variable ausgegeben. Bei Large Objects, die abgeschnitten wurden und deren tatsächliche Länge 32767 Byte überschreitet, wird immer 32767 (Maximal-Wert von SmallInt) ausgegeben.
Indikator-Variablen können nicht nur beim Empfangen von Daten, sondern auch in INSERT oder UPDATE-Statements verwendet werden, um in die entsprechende Spalte einen NULL-Wert zu schreiben.
Wie werden Indikator-Variablen definiert und verwendet
Indikator-Variablen müssen in RPG als Int(5) (entspricht SmallInt in SQL) definiert werden.
Wird mit Indikator-Variablen gearbeitet, muss die Indikator-Variable in embedded SQL-Statements unmittelbar (nur durch ein Leerzeichen getrennt), nach der Host-Variable, die geprüft werden soll, angegeben werden.
Syntax:
Exec SQL Select Col1, Col2, … ColN
Into :HostCol1 :IndCol1, :HostCol2 :IndCol2, … :HostColN :IndColN
Anmerkung: Es ist nicht zwingend erforderlich für alle Ausgabe-Variablen Indikator-Variablen zu definieren und anzugeben. Es genügt, nur für die Spalten, die NULL-Werte enthalten können, die entsprechenden Indikator-Variablen zu definieren und im SQL-Statement anzugeben.
Einzelne Host-Variablen und Indikator-Variablen:
Die Indikator-Variablen müssen dann als erstes nach der Prüfung des SQLCODEs oder des SQLSTATEs geprüft werden.
Achtung: Wird eine Indikator-Variable mit einem negativen Wert ausgegeben, bleibt der Wert in der Host-Variablen unverändert, d.h. es erfolgt keine Initialisierung der Ausgabe-Variablen!
In dem folgenden Beispiel wird die Auftragskopf-Datei (ORDERHDRX) mit dem Adress-Stamm (ADDRESSX) über einen LEFT OUTER JOIN verknüpft. Fehlt für einen Kunden die Adresse, werden in den Adress-Spalten NULL-Werte ausgegeben.
Aus dem Auftrags-Kopf werden die Spalten COMPANY (Firma), ORDERNO (Auftrags-Nr), CUSTNO (Kunden-Nr.) ausgelesen. Da durch den LEFT OUTER JOIN immer alle Zeilen (abh. von den WHERE-Bedingungen) aus der ersten Datei, also dem Auftrags-Kopf gelesen werden, und außerdem keine der Auftragskopf-Spalten NULL-Werte enthalten kann, müssen für diese Spalten weder Indikator-Variablen definiert noch angegeben werden.
Aus dem Adress-Stamm werden die Spalten CUSTNAME1 (Kunden-Name) und CITY (Ort) ausgelesen. Da es bei einem fehlenden Eintrag in dem Adress-Stamm zur Ausgabe von NULL-Werten kommen kann, wird sowohl für den Kunden-Namen als auch den Ort eine Indikator-Variable (INDCUSTNAME und INDCITY) als INT(5) angelegt.
Bei dem SELECT … INTO wird die jeweilige Indikator-Variable jeweils unmittelbar, nur durch ein Leerzeichen/Blank getrennt, nach der Host-Variablen angegeben. Nach dem Einlesen werden die Indikator-Variablen geprüft. Wurde ein NULL-Wert festgestellt, wird mit dem OpCode DSPLY eine entsprechende Meldung ausgegeben und die Host-Variable initialisiert.
 Quelle: Hauser
Quelle: HauserTipp: Um sicherzustellen, dass die Host-Ausgabe-Variablen keine falschen Werte enthalten, ist es am besten die Host- und Indikator-Variablen vor der Ausführung des SQL-Statements zu initialisieren!
Datenstrukturen und Indikator-Arrays:
In dem vorherigen Beispiel wurden die Host-Variablen und Indikator-Variablen einzeln definiert und geprüft. Vielfach ist es jedoch so, dass die Daten in eine externe oder auch intern beschriebene Datenstruktur ausgegeben werden sollen. Sofern NULL-Werte ausgegeben werden können, sind natürlich auch hier Indikator-Variablen erforderlich. In diesem Fall dürfen sie Indikator-Variablen jedoch weder einzeln noch in der Ausgabe-Datenstruktur definiert werden.
Stattdessen muss eine Feldgruppe/Array mit Indikator-Variablen angelegt werden und zwar mit so vielen Elementen wie die Datenstruktur Unterfelder hat. In das erste Element des Arrays wird dann der Wert der Indikator-Variablen für die erste Spalte bzw. Datenstruktur-Unterfeld ausgegeben, in das zweite Element der Wert für das zweite Datenstruktur-Unterfeld etc. Bei der Ausgabe wird das Indikator-Array unmittelbar nach der Host-Datenstruktur, nur durch ein Leerzeichen/Blank getrennt angegeben.
In dem folgenden Beispiel wird die Host-Datenstruktur HOSTDS definiert, in die bei der Ausführung des SELECT … INTO-Befehls alle Daten ausgegeben werden. Die Host-Datenstruktur enthält die Unter-Felder COMPANY (Firma), ORDERNO (Auftrags-Nr.), CUSTNO (Kunden-Nr.), CUSTNAME (Kunden-Name) und CITY (Ort). Der zugehörige Indikator-Array wird als Datenstruktur-Unterfeld in der Datenstruktur INDDS definiert. Auch wenn nicht für alle Datenstruktur-Unter-Felder NULL-Werte erwartet werden, muss das Array für alle Datenstruktur-Unterfelder ein Element enthalten.
In der Datenstruktur INDDS wird für jedes einzelne Datenstruktur-Unterfeld in der Datenstruktur HOSTDS ein Datenstruktur-Unterfeld angelegt, die durch den Indikator-Array überlagert werden. Die Definition der einzelnen Indikator-Unterfelder ist nicht erforderlich, vereinfacht jedoch das Handling bei der Prüfung der Indikator-Werte, insbesondere wenn viele Spalten ausgewählt werden.
Das Indikator-Array wird im SELECT … INTO-Statement unmittelbar nach der Host-Struktur angegeben. Die Datenstruktur, die das Indikator-Array enthält darf an dieser Stelle ebenso wenig angegeben werden wie einzelne Indikator-Variablen.
 Quelle: Hauser
Quelle: HauserEs ist auch möglich bei der gleichen Abfrage mit mehreren Ausgabe-Datenstrukturen (z.B. wenn Dateien verknüpft werden) zu arbeiten. In diesem Fall muss für jede Ausgabe-Datenstruktur ein Indikator-Array definiert werden. Das entsprechende Indikator-Array wird immer unmittelbar nach der zugehörigen Ausgabe-Datenstruktur nur durch Komma getrennt angegeben.
Verwendung von Indikator-Variablen in Insert und Update-Statements
Indikator-Variablen können sowohl in Verbindung mit einzelnen Variablen aber auch mit Datenstrukturen in INSERT oder SELECT-Statements verwendet werden. Dies ist besonders deshalb hilfreich, da die Verarbeitung von NULL-Werten in RPG etwas umständlich ist.
In dem folgenden Beispiel wird ein Datensatz in die Tabelle SALES geschrieben. In der Tabelle SALES gibt es die Spalten CUSTNO(Kunden-Nr.), ITEMNO (Artikel-Nr.), ITEM (Artikel-Bezeichnung), SALESDATE (Verkaufs-Datum) und AMOUNT (Umsatz. Die Spalten ITEM (Artikel-Bezeichnung) und SALESDATE sind beide NULL-fähig. Alle anderen Spalten dürfen keine NULL-Werte enthalten.
Die Artikel-Bezeichnung (ITEM) wird über eine SET-Anweisung aus der Tabelle ITEMMASTX (Artikel-Stamm) ermittelt. Sofern der Artikel (ITEMNO) nicht angelegt ist, wird ein NULL-Wert ausgegeben. Die Beschreibung wird in die Variable LOCDSINSUPD.ITMEM ausgegeben und ein NULL-Wert wird in die Indikator-Variable LOCDSIND.ITEM ausgegeben.
Das Verkaufsdatum (SALESDATE) wird dann auf NULL gesetzt, wenn die Variable LOCDSINSUPD.SALEDATE den ‘0001-01-01‘ beinhaltet. Auch hier wird der NULL-Wert in eine Indikator-Variable (LOCDSIND.ITEM) ausgegeben.
Beim INSERT-Statement wird für die beiden Spalten ITEM (Artikel-Bezeichnung) und SALESDATE (Verkaufsdatum) die jeweilige zugehörige Indikator-Variable angegeben.
Da alle anderen Spalten nicht NULL sein können, ist eine Angabe einer Indikator-Variablen nicht erforderlich.
 Quelle: Hauser
Quelle: Hauser
Das folgende Beispiel unterscheidet sich von dem vorherigen Beispiel nur dadurch, dass die Spalten beim Insert nicht einzeln aufgelistet werden, sondern stattdessen die Datenstruktur, die alle Spalten in der richtigen Reihenfolge beinhaltet, angegeben wird.
Da NULL-Werte übergeben werden können, muss ein Array mit Indikator Variablen (LOCDSIND2.ARRINS) für alle Spalten übergeben werden, auch wenn lediglich die beiden Spalten ITEM (Artikel-Bezeichnung) und SalesDate (Verkaufsdatum) NULL-Werte enthalten können.
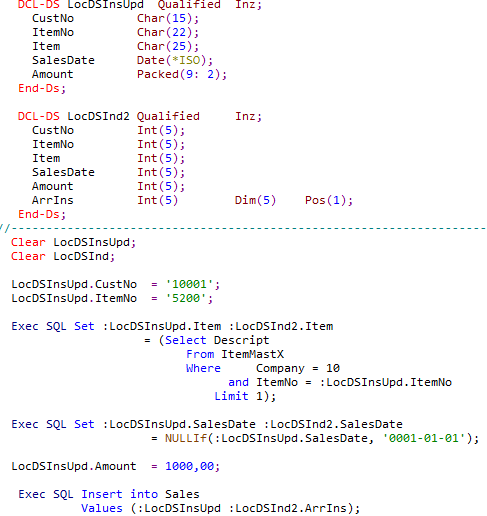 Quelle: Hauser
Quelle: Hauser
Gleiches gilt auch für das UPDATE-Statement, d.h. beim SET können Indikator-Variablen angegeben werden.
In dem folgenden Beispiel sollen die Spalten ITEM (Artikel-Bezeichnung), SALESDATE (Verkaufsdatum) und AMOUNT (Umsatz) in der Tabelle SALES upgedated werden. Wie in den vorherigen Beispielen wird die Artikel-Bezeichnung (ITEM) aus dem Artikel-Stamm (ITEMMASTX) ermittelt. Wird kein Artikel-Stamm gefunden wird ein NULL-Wert in die entsprechende Indikator-Variable (LOCDSIND.ITEM) ausgegeben.
Das Verkaufsdatum wird auf NULL gesetzt (bzw. die Indikator-Variable LOCDSIND.SALESDATE entsprechend angepasst), wenn die Variable LOCDSINSUPD.SALESDATE den Wert 0001-01-01 enthält. Im UPDATE-Statement wird für die beiden Spalten die Host-Variable (LOCDSINSUPD.ITEM bzw. LOCDSINSUPD.SALESDATE) und die zugehörigen Indikator-Variablen (LOCDSIND.ITEM bzw. LOCDSIND:SALESCATE) angegeben.
Die Umsatz-Spalte (AMOUNT) darf nie NULL sein, deshalb wird für diese Spalte keine Indikator-Variable angegeben.
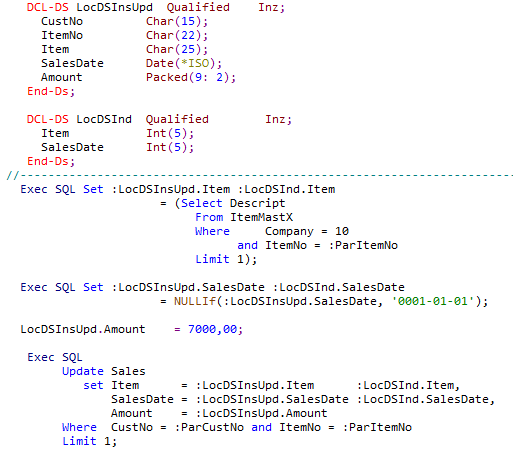 Quelle: Hauser
Quelle: Hauser
Es ist natürlich nicht zwingend erforderlich bei potentiellen NULL-Werten mit Indikator-Variablen zu arbeiten. Stattdessen können die zu erwartenden NULL-Werte auch mit einer der skalaren Funktionen COALESCE oder IFNULL gesetzt oder mit NULLIF Null-Werte wieder zurückgesetzt werden.
Soweit zur Behandlung von NULL-Werten in Verbindung mit Indikator-Variablen.
Und nun viel Spaß bei der Verarbeitung von NULL-Werten.
Birgitta Hauser ist IBM Champion und Spezialistin für SQL- sowie RPG-Programmierung.
Frau Hauser gibt regelmäßig Workshops im Rahmen der MIDRANGE ACADEMY.
Sie schreibt regelmäßig für MIDRANGE und den TechKnowLetter. Hier erhalten Sie brandneue, tiefe Informationen zu SQL, RPG und vielem mehr.
Der TechKnowLetter erscheint monatlich. Sechs Ausgaben erhalten Sie für 88 Euro hier.