

Es ist schon schade, dass IBM hier und da Implementierungen von Funktionen und Anwendungen ein wenig „lustlos“ durchzuführen scheint. Es hat in der Vergangenheit immer wieder Beispiele gegeben, die Kunden verärgert oder gar abgeschreckt haben, nützliche Funktionen auf dem System i einzusetzen. Der Grund war dabei häufig, dass die Standardimplementierung nicht optimal gelöst war. Ähnlich verhält es sich beim Einsatz von Tomcat mit IBM i.
Wie wir bereits zuvor gesehen haben, wird Tomcat im Standard im Subsystem QINTER ausgeführt. Damit gibt es keine wirkliche administrative Unterscheidung zu Dialogjobs, die im Regelfall auch im Subsystem QINTER ausgeführt werden. Das ist ein Manko, welches man als erfahrender IBM-i-Administrator relativ einfach beseitigen kann. Denn mit einigen wenigen Konfigurationsschritten lässt sich der Tomcat auf IBM i auch so ausführen, dass er sich klar von interaktiven Jobs abgrenzt. Das Transferieren von Tomcat in ein – im Idealfall eigenes – Subsystem erlaubt es uns, performancebeeinflussende Einstellungen gezielt vorzunehmen. Damit erreichen wir nicht nur verbesserte Ausführungsgeschwindigkeiten für die Tomcat-Anwendungen, sondern unter Umständen auch eine Entlastung der Anwendungen, die ansonsten zusammen mit dem Tomcat in einem Subsystem ausgeführt werden und sich die zugeordneten Ressourcen teilen müssen.
Nachfolgend möchte ich Ihnen zeigen, wie Sie den Tomcat in einem eigenen Subsystem ausführen können. Aber mit einem eigenen Subsystem allein ist es nicht getan – denn erst zugehörige IBM-i-Spezifika, wie zum Beispiel Routingeinträge, Warteschlangenzuordnungen etc., führen letztlich zum Ziel. Auch diese Einstellungen werden wir nachfolgend behandeln.
Damit wir die geänderten Tomcat-Einstellungen getrennt von der Basisinstallation beeinflussen und steuern können, empfiehlt es sich, die nachfolgenden Einstellungen in einer separaten Bibliothek vorzunehmen. Für unser Beispiel nutze ich dazu die Bibliothek USRTOMCAT.
Diese Bibliothek erstelle ich mit dem Befehl CRTLIB USRTOMCAT.
CRTLIB USRTOMCAT
In der Bibliothek USRTOMCAT legen wir nun alle IBM-i-Spezifika an, die wir für die angepasste Tomcat-Installation benötigen. Das sind im Einzelnen:
- eine Jobwarteschlange (JOBQ)
- eine Jobbeschreibung (JOBD)
- eine Klasse (CLS)
- eine Subsystembeschreibung (SBSD)
- ein Jobwarteschlangeneintrag (JOBQE)
- ein Routing-Eintrag (RTGE)
Jobwarteschlange
Die IBM-i-Architektur bedient sich zur Differenzierung der unterschiedlichen Jobs und deren Systembelastung der Jobwarteschlange. Jobwarteschlangen können bei Bedarf individuell definiert werden. Damit der Tomcat auf dem System IBM i eigenständig, das heißt ohne maßgebliche Beeinflussung anderer Jobs ausgeführt werden kann, empfehle ich, für ihn ein separates Subsystem zu definieren. Damit sind wir hinsichtlich der möglichen Einstellungen am flexibelsten.
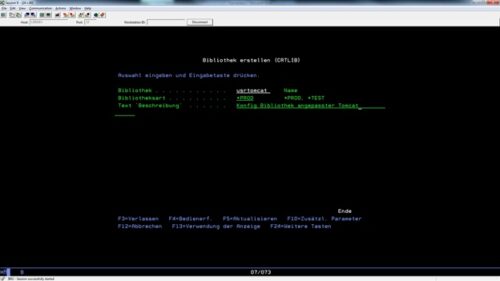
In unserem Beispiel legen wir daher eine Jobwarteschlange TOMJOBQ an. Dazu verwenden wir den Befehl CRTJOBQ. Die Jobwarteschlange legen wir in unserer Bibliothek USRTOMCAT an.
CRTJOBQ
Jobbeschreibung
Die Tomcat-Jobs lassen sich hinsichtlich ihrer Ausführungskriterien prima steuern. Damit wir auch sie flexibel administrieren können, legen wir wieder eine eigene Jobbeschreibung an.
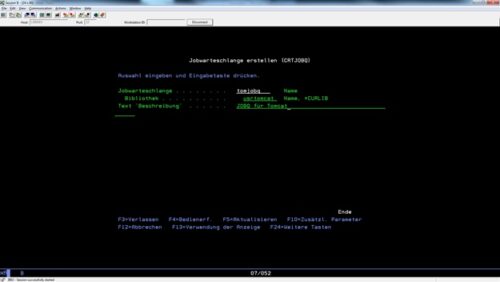
Die Jobbeschreibung (JOBQ) erstellen wir mit dem Befehl CRTJOBD. Auch die Jobbeschreibung legen wir in der Bibliothek USRTOMCAT ab und ordnen sie der Jobwarteschlange TOMJOBQ zu:
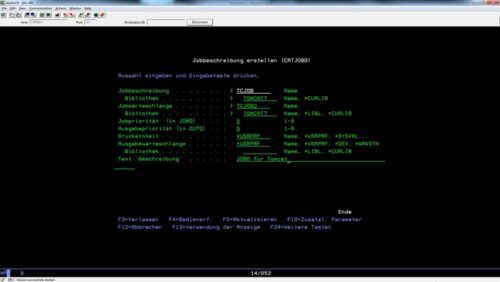
CRTJOBQ
Klassendefinition
Die Ausführungsattribute für die Tomcat-Jobs werden mittels der Klassendefinitionen festgelegt. Diese sind nicht mit Java-Klassen zu verwechseln! In den Klassendefinitionen können wir unter anderem einige performancesensitive Parameter hinterlegen, wie zum Beispiel die Zeitscheibe, den maximal zuordenbaren Speicher und weitere Attribute. Auch die neue Tomcat-Klasse wird in der Bibliothek USRTOMCAT angelegt:
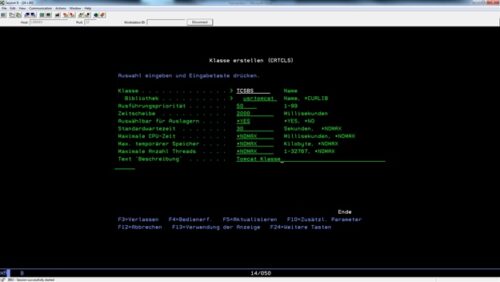
CRTCLS
Subsystembeschreibung
Die Subsystembeschreibung definiert, in welchem Maße Jobs, die in diesem Subsystem ausgeführt werden, Hauptspeicher konsumieren können. Mit der Zuordnung zu den Speicherpools definiert der IBM-i-Administrator die Grundfesten für die in dem Subsystem auszuführenden Jobs. IBM bietet uns an dieser Stelle die Möglichkeit, auf bestehende IBM-i-Pooldefinitionen zurückzugreifen oder eigene benutzerdefinierte Pools zu definieren. Die meiste Flexibilität bieten die privaten Pools – denn ihnen kann zum Beispiel ein fester Hauptspeicherbereich zugeordnet werden, der dann die übrigen Jobs auf dem System nur sekundär beeinflusst. In unserem Beispiel gehen wir aber davon aus, dass das System i mit ausreichend Hauptspeicher ausgestattet ist und die parallele Verwendung von Pools die bereits auf dem System laufenden Prozesse nicht wesentlich negativ beeinflusst.
Die nachfolgende Abbildung (WRKSYSSTS) zeigt die auf dem System i existierenden Pools und deren Hauptspeicherzuordnung:
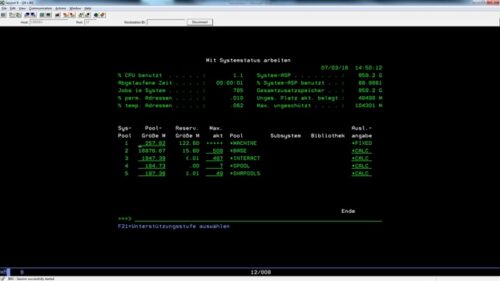
WRKSYSSTS und die Auflistung der Pools
Wir ordnen unsere Subsystembeschreibung in diesem Beispiel dem Pool 1 (Machine Pool) mit einer Speichergrößenzuordnung und einem Auslastungsgrad zu.
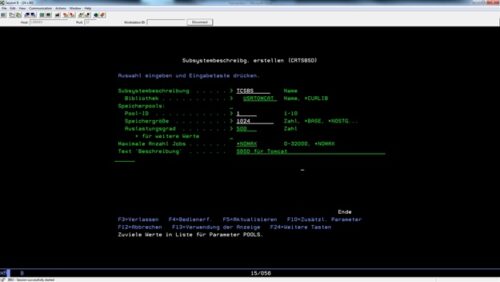
CRTSBSD
Bei der Speichergrößeneinheit handelt es sich um KB. Bei dem Auslastungsgrad handelt es sich um die maximale Anzahl parallel laufender Threads in diesem Pool.
Gerade diese beiden Werte können die Ausführungsgeschwindigkeit maßgeblich beeinflussen! Es kommt letztlich auf die Anwendungen an, die mit Tomcat ausgeführt werden. Prüfen Sie deshalb diese Einstellungen im laufenden Betrieb sehr genau hinsichtlich möglicher Auslagerungen oder Paging-Raten. Sind diese zu hoch, dann können Anpassungen an der Speichergröße und/oder dem Auslastungsgrad mitunter Wunder bewirken!
Deployen von Webanwendungen auf Tomcat
Basierend auf der Implementierung von Tomcat mit unserem HTTP Server for i können wir nun auch die entsprechenden Anwendungen auf dem Server bereitstellen.
Schauen wir uns das anhand einer Datenbankabfrage an, die wir mit einer Beispielanwendung auf unsere DB2/UDB durchführen. Diese Anwendung liefert uns einen Vergleich bei den Zugriffsmethoden auf die DB2-Inhalte.
Dabei sind die Datenbankzugriffsdefinitionen leider in verschiedenen Konfigurationsdateien vorzunehmen. Wünschenswert wäre eine einfachere Hinterlegung – aber diese Einstellungsschritte müssen nur einmalig vorgenommen werden.
Damit wir einen Zugriff auf die Datenbank erhalten, müssen wir neben dem Namen der Datenbank auch die Login-Informationen (IBM-i-Benutzer und IBM-i-Kennwort) hinterlegen. Basierend auf dem JDBC-Treiber, der auch nativ von Java-Anwendungen genutzt werden kann, lässt sich dann ein Zugriff auf die Datenbankinhalte des IBM i durchführen. Die Zugriffe führen wir hier mit dem jt400.jar durch.
Damit wir die notwendigen Einstellungen durchführen können, ist eine Erweiterung der Konfigurationsdatei server.xml erforderlich.
Die Erweiterungen sind folgende:
- Authentifizierungstype
- Hier sind die Angaben „Application“ oder „Container“ möglich.
- driverClassName
- vorqualifizierter Name des JDBC-Treibers. In unserem Beispiel ist das der Standardtreiber com.ibm.db2.jcc.DB2Driver
- name
- Hier ist der qualifizierte Name der Datenquelle anzugeben.
- Username
- Benutzername für den JDBC-Zugriff
- Password
- Kennwort für den JDBC-Zugriff
- Type
- Hier ist der qualifizierte Java-Klassenname für den Zugriff anzugeben.
- url
- Hier ist die Verbindungs-URL für den JDBC-Treiber anzugeben.
- initialSize
- Anzahl der initial zu erstellenden Verbindungen
- maxActive
- Anzahl der maximal parallel zulässigen Verbindungen
- minIdle
- Minimale Anzahl der Verbindungen, die sich zeitgleich im Leerlauf befinden können
- maxIdle
- Maximale Anzahl der Verbindungen, die sich zeitgleich im Leerlauf befinden können
- maxWait
- Maximale Dauer (in Millisekunden) für Warten auf Rückantwort
Öffnen Sie diese Erweiterungen mit einem geeigneten Editor und fügen Sie im Bereich GlobalNamingResources die nachfolgenden Zeilen in den Code ein:
Resource auth=“Container“
driverClassName=“com.ibm.db2.jcc.DB2Driver“
name=“jdbc/TEST“
username=“WWinzig“
password=“abcdefgh“
type=“javax.sql.DataSource“
url=“jdbc:as400://ibmi;prompt=false;translate binary=true; extended metadata=true“
maxActive=“20″
minIdle=“4″
maxIdle=“10″
maxWait=“10000″
validationQuery=“Select 1″
/>
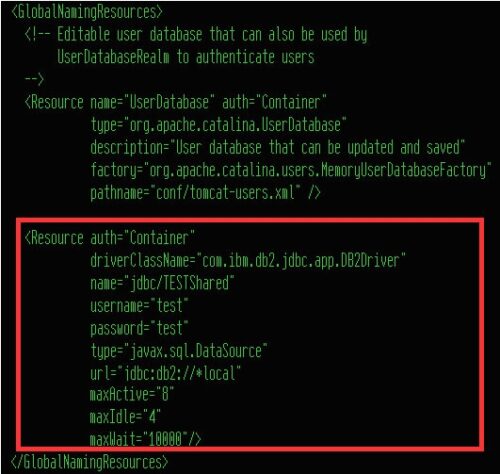
Eingefügte Source-Zeilen
Nachdem wir diese Angaben in der Datei server.xml durchgeführt haben, sind noch Ergänzungen in der Konfigurationsdatei web.xml notwendig. Öffnen Sie diese Datei in einem geeigneten Editor und fügen Sie die folgenden Zeilen ein, damit der Zugriff auf die definierten Daten ermöglicht wird:
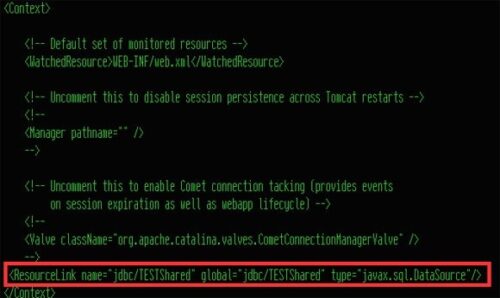
Anpassungen an der Server.xml-Datei
Nun müssen noch Einstellungen an der Konfigurationsdatei TomcatTestServlets/WebContent/WEB-INF/web.xml vorgenommen werden. Mit den einzufügenden Zeilen verweisen wir auf die Datenquelle, die zuvor in der Datei server.xml hinterlegt worden ist.
resource-ref
res-ref-name /jdbc/TEST /res-ref-name
res-type javax.sql.DataSource res-type
res-auth Container res-auth
/resource-ref
Jetzt übertragen wir die Datei TomCatTestServlets.war in das Home-Verzeichnis des Tomcat Servers /home/download/apache-tomcat-7.0.28/webapps.
Als Nächstes geben wir einen neuen Einstiegspunkt für die Beispielanwendung an. Dazu müssen Sie den Eintrag JKMount/TomcatTestServlets/* worker1 in die Datei httpd.conf einfügen.
Nach einem Neustart des Tomcat und der Eingabe der Start-URL für unsere Beispielanwendung wird diese erstmalig ausgeführt.
Die Performance von Anwendungen kann oftmals durch einige wenige Einstellungen beeinflusst werden. Dabei wollen wir natürlich den Fokus auf die Verbesserung der Performance legen.
Eine Besonderheit beim Einsatz von Tomcat zusammen mit dem System i liegt in der Kommunikation zwischen den beiden Welten sowie in der SQL-Ausführung. Im Regelfall wird mit jedem Aufruf die Verbindung zum System neu aufgebaut. Mit gewissen Einstellungen lässt sich das umgehen – und kann signifikante Performancesteigerungen nach sich ziehen. Die Basis dafür bilden die sogenannten Connection Pools.
Bei einem Connection Pool definieren wir das Verhalten des Tomcat hinsichtlich der Zieldatenbank – in unserem Fall der DB2-UDB des System i. Dabei werden die Zugriffe auf die Datenbank in der Form gesteuert, dass sie während der Laufzeit des Tomcat Servers geöffnet bleiben. Damit entfällt eine der performanceintensivsten Aktionen in Verbindung mit Webanwendungen und Datenbankzugriffen. Wir können je nach Anwendungsstruktur festlegen, wie viele Verbindungen zu der Datenbank geöffnet werden sollen und damit einer Nutzung zur Verfügung stehen. Die Anzahl der parallel zu verwendenden Pools ist damit stark auf die Anwendungen bezogen, die in Ihrem Unternehmen unter Tomcat laufen und Zugriffe auf die DB2-UDB des System i benötigen.
Die Einrichtung der Connection Pools basiert auf der Erstellung eines dynamischen Web-Projekts, das wir zum Beispiel in RDi/RDP anlegen können.
Dazu erstellen wir zunächst ein neues dynamisches Web-Projekt über die Menüauswahl „Datei/Neu/Projekt/Webprojekt“.
Als Erstes geben wir dem neuen Projekt einen Namen – in unserem Fall „TomCatConnectionPool“.
Basierend auf der Anwendungsbasisdatei context.xml erstellen wir uns nun die notwendigen Komponenten. Mit dem Anlegen eines neuen Projekts hat Rational uns bereits die Basisstruktur vorgegeben – unter anderem finden wir dort jetzt auch das Verzeichnis META-INF. Dieses Verzeichnis nutzen wir, um dort unsere contect.xml-Datei zu erstellen. Dazu markieren wir das Verzeichnis META.INF und klicken mit der rechten Maustaste die Option „Neu/Datei“ an.
Neue Datei anlegen
In dem Definitionsfenster für die neue Datei geben wir als Namen „context.xml“ ein und bestätigen die Eingabe mit einem Klick auf „Fertig stellen“.
Contect.xml anlegen
{kind=link}