

Durch die SQL Data Definition Language (DDL) werden Datenbanken-Objekte, wie Tabellen, Views und Indices generiert. DSazu wurden die SQL DDS mit den letzten Releases und Technology Refreshes massiv erweitert. DDS (Data Description Specifications), die traditionelle Methode zum Erstellen von physischen und logischen Dateien, wurde dagegen auf dem Stand von Release V5R3M0 eingefroren.
Auch wenn die SQL DDL gegenüber DDS viele Erweiterungen bietet, war die Integration von Feld-Referenz-Dateien lange nicht unterstützt. Dieses Manko kann nun, dank der Erweiterung CREATE OR REPLACE TABLE ad acta gelegt werden. In diesem Artikel wird die Verwendung von Referenz-Dateien in Verbindung mit SQL-Tabellen beschrieben.
Feld-Referenz-Dateien/Tabellen
Eine Feld-Referenz-Datei oder Referenz-Tabelle enthält keine Daten, jedoch ein Referenz-Feld/Spalte für jedes innerhalb der Anwendung verwendete Feld. In den DDS-Beschreibungen von physischen und Dateien, aber auch von Display-Files und Printer-Files, können Felder basierend auf einem Referenz-Feld definiert werden. Der Bezug zu dem Referenz-Feld wird in der DDS-Beschreibung hinterlegt bei der Definition des Feldes hinterlegt. Beim Erstellen des Objektes, werden die Referenz-Informationen ausgelesen und die Felder basierend auf der Referenz generiert. Felder aus der Feld-Referenz-Datei können nicht nur in DDS-Beschreibungen verwendet werden, sondern auch zum Definieren von Variablen, z.B. im RPG Quell-Code.
Ändert sich eine Feld-Beschreibung in der Referenz-Datei, müssen lediglich die Objekte (physische und logische Dateien, Display-Files, Printer-Files aber auch Module und Programme) in denen das Referenz-Feld verwendet wird neu erstellt werden. Eine Änderung oder Überarbeitung des vorhandenen Quell-Codes ist, mit der Ausnahme von Display und Printer-Files, nicht erforderlich.
Sofern sämtliche Felder in physischen und logischen Dateien, Display- und Printer-Files, sowie die im Quell-Code verwendeten Variablen mit Bezug auf Felder in einer Feld-Referenz-Datei definiert wurden, können Feld-Überläufe und abgeschnittene Daten bei Änderung des Referenz-Feldes so gut wie ausgeschlossen werden.
Für SQL-beschriebene Tabellen war bislang die Verwendung von Referenz-Dateien und Spalten nicht möglich. Zum einen, weil Feld-Referenz-Tabellen nicht im SQL-Standard beschrieben sind, zum anderen, weil es in einer vollständig normalisierten Datenbank keine Redundanzen gibt, d.h. jedes Feld/Spalte wird nur einmalig definiert wird. Allerdings handelt es sich bei vollständig normalisierten Datenbanken eher um eine theoretische Größe. Datenbanken sind immer zu einem gewissen Grad de-normalisiert.
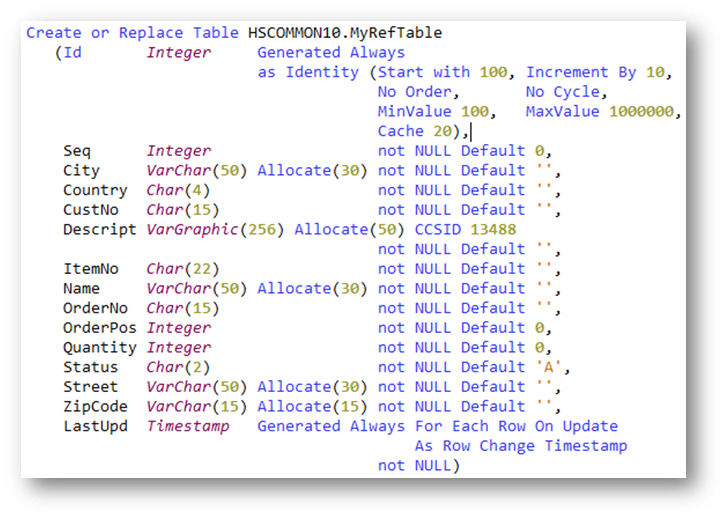 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 1: SQL beschriebene Feld-Referenz-Tabelle
SQL-Tabellen können zwar mit CREATE TABLE … AS (SELECT …) basierend auf einer Feld-Referenz-Datei erstellt werden, die Referenz-Informationen (Referenz-Feld und -Datei) werden jedoch nicht gespeichert. Stattdessen werden die Referenzen aufgelöst, in die absoluten Spalten-Definitionen übersetzt und als solche implementiert. Wird nun ein Referenz-Feld geändert, muss manuell geprüft werden, in welchen Tabellen, Spalten basierend auf diesem Referenz-Feld definiert wurden. Um die geänderten Spalten-Definitionen in die vorhandenen Tabellen zu integrieren, ist die Ausführung von entsprechenden ALTER TABLE-Statements erforderlich. Die Gefahr, dass dabei die eine oder andere Spalte auf der Strecke bleibt ist immens.
Erst seit der Erweiterung OR REPLACE im CREATE TABLE-Statement können Referenz-Dateien auch in SQL sinnvoll eingesetzt werden. Bei einer Änderung von Referenz-Feldern ist eine Durchforstung der aktuellen Spalten-Definitionen und zusätzliche Erstellung und Ausführung von ALTER TABLE Statements nicht länger erforderlich. Stattdessen wird lediglich das SQL-Skript, das das CREATE OR REPLACE TABLE-Statement enthält, erneut ausgeführt. Dabei bleiben die Daten bleiben erhalten und die abhängigen Objekte, wie Views und Indices werden entsprechend angepasst.
Schauen wir uns doch ein Beispiel an: Die Abbildung 1 zeigt das Erstellungs-Skript für die SQL-beschriebene Referenz-Tabelle MYREFTABLE. In dieser Referenz-Tabelle sind eine Reihe von Spalten mit unterschiedlichen Namen, Datentypen, Längen, CCSIDs sowie Unterlassungs-Werten definiert.
Daneben enthält diese Tabelle Spalten mit speziellen SQL-Attributen wie eine Identity Column (Spalte ID) oder eine Zeitmarke, in die bei jedem Insert, Update oder Write der aktuelle Änderungs-Zeitpunkt übernommen wird (Spalte LASTUPD).
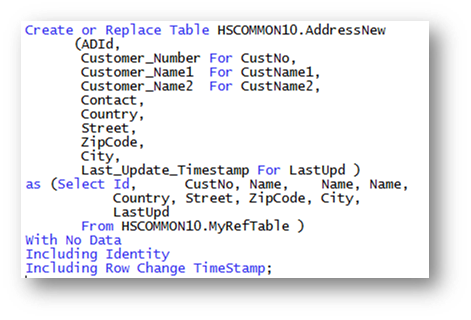 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 2: Tabelle ADDRESSNEW basierend auf der Referenz-Tabelle MYREFTABLE
Die Abbildung 2 zeigt das Erstellungs-Statement für die Tabelle ADDRESSNEW in der Bibliothek HSCOMMON10. Die Tabelle wird basierend auf der Feld-Referenz-Datei MYREFFILE auf die in dem SELECT-Statement Bezug genommen wird erstellt.
Die Spalten-Namen, die in die zu erstellenden Tabelle integriert werden sollen, werden vor dem SELECT-Statement definiert. Für Spalten-Namen, die 10 Zeichen nicht überschreiten, z.B. COUNTRY oder STREET, wird nur ein Name angegeben. Für Spalten-Namen, die 10 Zeichen überschreiten, wird zusätzlich zu dem langen SQL-Namen ein kurzer (<= 10 Zeichen langer) System-Name definiert. Die Anzahl der aufgelisteten Spalten, muss der Anzahl der im SELECT-Statement ausgewählten Spalten entsprechen.
In diesem Beispiel werden zwei Namensfelder (CUSTOMER_NAME1, CUSTOMER_NAME2), sowie die Spalte CONTACT in die Tabelle integriert. Da alle drei Felder mit Bezug auf das Referenz-Feld NAME definiert werden sollen, wird die Spalte NAME im SELECT-Statement mehrfach (genau 3 Mal) angegeben.
Bei der Definition der Tabelle über ein SELECT-Statement und mit CREATE OR REPLACE ist die Angabe von WITH NO DATA erforderlich. Nur dann kann das SQL-Statement auch später erneut ausgeführt werden, ohne dass die in der Tabelle vorhandenen Daten verloren gehen.
Die Angabe INCLUDING IDENTITY bewirkt, dass von der Referenz-Spalte ID nicht nur der Datentyp, sondern auch die Identity-Attribute, also GENERATE ALWAYS AS IDENTITY … , übernommen werden. Da pro Tabelle jedoch nur eine einzige Identity-Spalte integriert werden kann, darf die Spalte ID nur einmalig ausgewählt werden. Sofern weitere Spalten mit der gleichen Definition wie die Spalte ID (jedoch ohne die Identity-Attribute) definiert werden müssen, z.B. für Fremd-Schlüssel / Foreign Keys, ist zusätzliche Referenz-Spalte mit der gleichen Definition erforderlich.
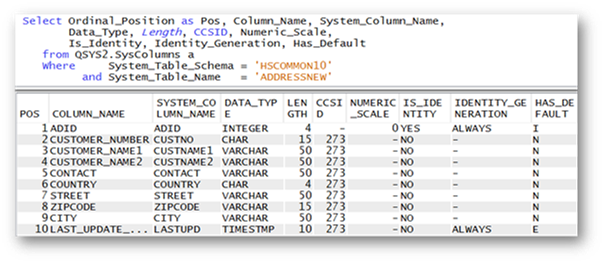 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 3: Auszug aus Catalog View SYSCOLUMNS für Tabelle ADDRESSNEW
Die Angabe ROW CHANGE TIMESTAMP bewirkt, dass für das Feld nicht nur die Zeitmarken-Definition, sondern auch die Änderungs-Attribute übernommen werden. Da pro Tabelle nur eine einzige Spalte mit dem ROW CHANGE TIMESTAMP-Attribut definiert werden kann, darf die Referenz-Spalte LASTUPD im SELECT-Statement auch nur einmalig ausgewählt werden.
Die Abbildung 3 zeigt einen Auszug aus der Catalog-View SYSCOLUMNS, in dem alle Spalten der Tabelle ADDRESSNEW mit ihren Definitionen und Attributen aufgelistet wurden.
Sobald Daten in die Tabelle geschrieben bzw. geändert werden, werden die Spalten ADID und LAST_UPDATE_TIMESTAMP automatisch aktualisiert.
Das in Abbildung 4 gezeigte Beispiel stellt einen Auszug aus der Tabelle ADDRESSNEW dar, nach dem über einen Massen-Insert Datensätze in die Tabelle übernommen wurden. Die Identity-Spalte wurde korrekt hochgezählt. Die Aktualisierungszeit ist für alle Einträge identisch, da die Daten durch ein einziges INSERT-Statement übernommen wurden.
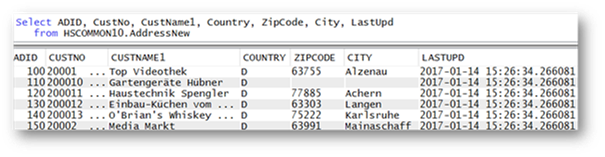 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 4: Tabelle ADDRESSNEW – Nach Datenübernahme
Datei-Erweiterung
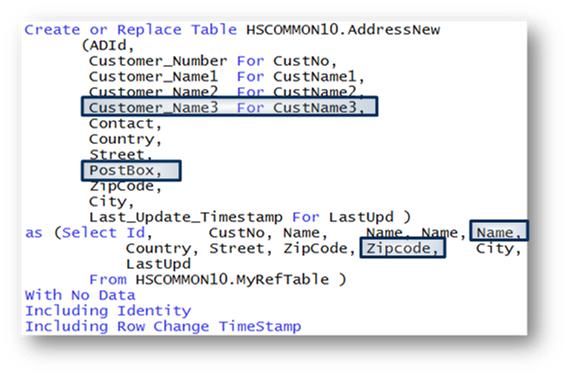
Die Tabelle ADDRESSNEW muss nun um einige Spalten erweitert werden. So ist eine dritte Namens-Spalte CUSTOMER_NAME3 erforderlich, die nach der Spalte CUSTOMER_NAME2 eingefügt werden soll. Die neue Namens-Spalte muss genau so wie die bereits vorhandenen Namens-Spalten, also basierend auf dem Referenz-Feld (NAME) definiert werden.
Ebenso muss eine Spalte POSTBOX nach der Spalte STRASSE mit der gleichen Definition wie die Postleitzahl (Spalte ZIPCODE) integriert werden. Für diese Erweiterungen muss in dem SQL-Skript bzw. in dem CREATE OR REPLACE TABLE-Statement lediglich die Spalten-Liste und das SELECT-Statement angepasst werden. Dabei werden die neuen Spalten bzw. Referenz-Felder an den gewünschten Stellen eingefügt, wie das Beispiel in Abbildung 5 zeigt.
 Quelle: Biritta Hauser
Quelle: Biritta Hauser
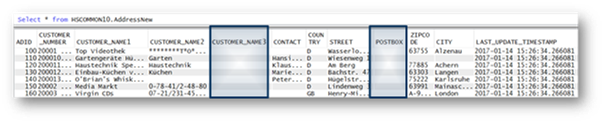
Ändern Tabelle ADDRESSNEW – Einfügen von zusätzlichen SpaltenDamit die Änderungen wirksam werden, muss lediglich das geänderte CREATE OR REPLACE TABLE-Statement erneut ausgeführt werden. Führt man nach der erneuten Ausführung des modifizierten CREATE OR REPLACE TABLE-Statements einen einfachen SELECT * FROM aus, erkennt man, dass eine Spalte CUSTOMER_NAME3 ohne Inhalt nach der Spalte CUSTOMER_NAME2 und vor der Spalte CONTACT eingefügt wurde. Ebenso erscheint eine zusätzliche Spalte (POSTBOX) zwischen den Spalten STREET und ZIPCODE.
Das Beispiel in Abbildung 6 zeigt das Ergebnis des SELECT-Statements.
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 6: Tabelle ADDRESSNEW nach dem Einfügen von neuen Spalten
Die nächste Abbildung (Bild 7) zeigt einen weiteren Auszug aus der Catalog View SYSCOLUMNS, aus dem ersichtlich ist, dass die neuen Spalten an (Ordinal) Position 5 und 9 eingefügt wurden.
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAuszug aus Catalog View SYSCOLUMNS nach dem Hinzufügen von Spalten
Änderung von Referenz-Feldern
Das Hinzufügen von neuen Spalten, die basierend auf einem Referenz-Feld definiert wurden ist eine Sache. Was mindestens genauso häufig vorkommt, ist, dass Referenz-Felder geändert werden müssen.
In einem solchen Fall, muss das CREATE OR REPLACE TABLE-Statement für die Feld-Referenz-Datei angepasst werden. Auch hier können neue Spalten an jeder Stelle eingefügt werden. Dies könnte erforderlich sein, wenn die Referenz-Spalten nach Alphabet angeordnet werden sollen.
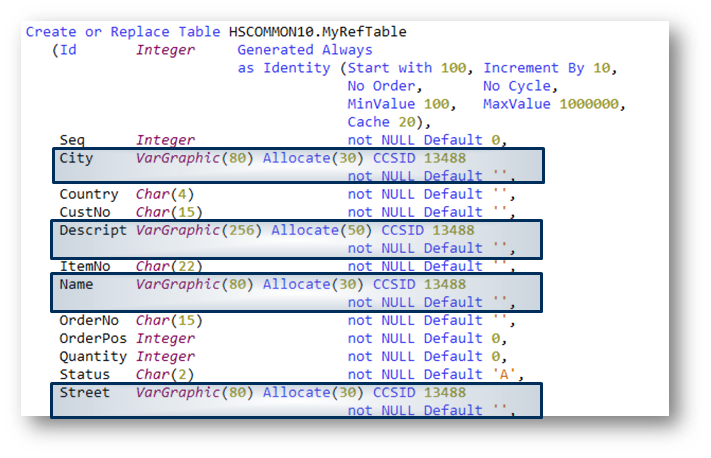
In unserem Beispiel werden die alphanumerischen Referenz-Spalten CITY, NAME und STREET von einer Single-Byte-Character-Definition (VARCHAR) in eine Double-Byte-Character-Definition (VARGRAPHIC mit CCSID 13488 = UCS2) konvertiert. Des Weiteren werden die Spalten-Längen von 50 Zeichen auf 80 Zeichen erweitert. Der allokierte Bereich, also die maximale Anzahl Zeichen, die tatsächlich in die Spalte (und nicht in die Overflow-Area) geschrieben werden, bleibt unverändert.
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 8: Modifizierte Feld-Referenz-Tabelle MYREFTABLE
Um die Änderungen in die Referenz-Tabelle zu übernehmen, muss lediglich das SQL-Skript mit dem modifizierten CREATE OR REPLACE TABLE-Statement erneut ausgeführt werden.
Nachdem die Referenz-Datei aktualisiert wurde, müssen die Erstellungs-Skripts bzw. die CREATE OR REPLACE STATEMENTS der abhängigen Tabellen erneut ausgeführt werden. Eine Änderung des Quell-Codes oder gar die händische Ausführung von entsprechenden ALTER TABLE-Statements ist nicht länger erforderlich.
In den beiden folgenden Abbildungen (9 und 9a) wird zunächst ein Auszug aus der Calalog View SYSCOLUMNS für die Tabelle ADDRESSNEW vor und im Anschluss nach dem erneuten Ausführen des CREATE OR REPLACE TABLE-Statements für die Tabelle ADDRESSNEW gezeigt.
Die Namens-Felder CUSTOMER_NAME1, CUSTOMER_NAME2, CUSTOMER_NAME3, sowie CONTACT wurden in UCS2 konvertiert und auf 80 Zeichen erweitert. Gleiches gilt für die Spalten STREET und CITY.
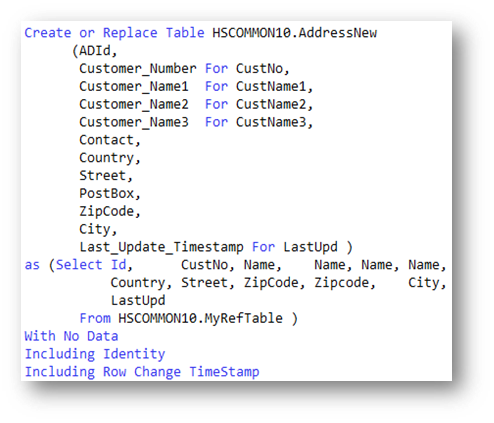
Abbildung 9
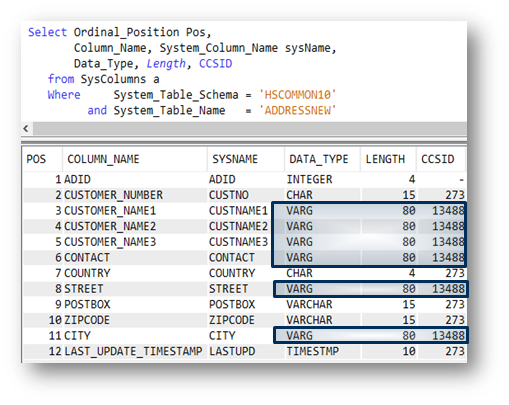 Quelle: Birgitta Hauser
Quelle: Birgitta HauserAbbildung 9 und 9a: Beschreibung der Tabelle ADDRESSNEW nach Änderung von Referenz-Spalten.
Jetzt müssen lediglich nur noch die Display-Files und Printer-Files angepasst und erneut erstellt werden. Ebenso müssen die Module, Programme und Service-Programme, die auf Referenz-Felder und die geänderten Tabellen zugreifen neu erstellt werden, und schon sollte alles problemlos, jedoch mit den geänderten Feld-Definitionen laufen.
Soweit zum Thema SQL und Referenz-Tabellen und nun viel Spass beim Erstellen und Integrieren von Referenz-Tabellen und -Felder.
Birgitta Hauser
Hier geht es zum „Vorgängerbeitrag“
{kind=link}