

Bevor wir uns im Detail mit den ILE-Konzepten (Integrated Language Environment) beschäftigen, sollten zunächst die unterschiedlichen Programmierkonzepte miteinander verglichen und gegeneinander abgegrenzt werden. In diesem Artikel werden die Unterschiede zwischen den Programmierkonzepten OPM (Original Program Model), den ILE-Konzepten und der Objekt-Orientierten Programmierung herausgearbeitet.
Man unterscheidet im Groben zwischen den folgenden Programmierkonzepten:
- Original Program Model (OPM)
- Integrated Language Environment (ILE) und
- Object Oriented Programming (OOP).
Original Program Model
Unter dem Original Program Model versteht man die klassische, auch durch den RPG-Zyklus bedingte Top-Down-Programmierung. Bei diesem Modell werden nur monolithische Programme erzeugt. Innerhalb der Programme können nur globale Variablen definiert und verwendet werden, das heißt, jede einzelne Variable kann sowohl im Hauptprogramm als auch aus jeder einzelnen Subroutine verändert werden.
Eine Strukturierung des Source Codes in OPM-Programmen kann durch Subroutinen oder aber durch den Aufruf von weiteren (Unter-)Programmen erfolgen. Wird der gleiche Source Code in mehreren Programmen benötigt, so wird er in der Regel kopiert und gegebenenfalls modifiziert.
Eine Auslagerung in Copy-Strecken oder in eigene Unterprogramme findet eher selten statt. Bei einer Änderung muss dann jede kopierte Version gefunden und modifiziert werden, was zum einen hohen Zeitaufwand erfordert und zum anderen fehleranfällig sein kann.
Klassische RPG- und Cobol-Programme sind in diesem Stil geschrieben. Viele dieser Programme wurden bereits vor langer Zeit erstellt und von einer Vielzahl von Programmierern über die Jahre hinweg ständig erweitert – wobei die Strukturierung oft auf der Strecke blieb. Das Ergebnis sind schwer zu wartende Programme. Von einer Neuprogrammierung wird in der Regel abgesehen, da niemand mehr so genau weiß, was in den Programmen alles integriert ist und i.d.R. eine detaillierte Dokumentation nicht vorhanden ist. Eine Modernisierung solcher Programme mit Hilfe der ILE-Konzepte ist jedoch möglich.
Integrated Language Environment
Im Gegensatz zu OPM ermöglicht ILE eine wesentlich modularere Programmierung. Neben Programmen können interne und exportierte Prozeduren und Funktionen erstellt werden. Interne Prozeduren sind verbesserte Subroutinen, die innerhalb des Programms/Moduls mit Parametern aufgerufen werden können. Obwohl innerhalb der Prozeduren globale Variablen verarbeitet werden können, sollte dies so weit möglich vermieden werden, und die notwendigen Informationen über Parameter ausgetauscht werden.
Ein Vorteil von internen Prozeduren gegenüber Subroutinen liegt darin, dass sowohl Variable, als auch Dateien innerhalb der Prozedur definiert werden können, die nur in dieser Prozedur verwendet werden können (lokale Variablen und Dateien). Damit können Programmteile innerhalb des Source Codes gekapselt werden. Bei einer Änderung muss lediglich dieser Programmteil beachtet werden.
Exportierte Prozeduren können nicht nur innerhalb der gleichen Teildatei (Modul), sondern auch von allen anderen Programmen und Prozeduren aufgerufen werden. Der Source Code wird nur einmal in einer Prozedur hinterlegt, die beliebig aufgerufen werden kann. Ist eine Änderung erforderlich, so muss sie nur an einer einzigen Stelle vorgenommen werden. Da exportierte Prozeduren von überall aufgerufen werden können, ist es ein Leichtes eine einzelne Prozedur zu testen. Damit wird der Wartungsaufwand im Vergleich zu OPM-Programmen beträchtlich reduziert.
Für die ILE-Programmierung wurde eine Reihe neuer Objekte und Objektarten eingeführt:
- Modul: Kleinste Compile-Einheit, das heißt, aus einer Teildatei wird genau ein Modul erstellt. In der ILE-Umgebung können Programm-Teile in unterschiedlichen Programmier-Sprachen geschrieben sein. Bevor die Einzelteile zu einem Programm gebunden werden können, muss der Quell-Code durch den jeweiligen Sprachen-Compiler umgewandelt werden. Das Ergebnis dieser Kompilierung ist ein Modul.
- Programm: In ILE-Umgebungen kann sich ein Programm aus mehreren Modulen zusammensetzen. Programme können direkt, z.B. aus anderen Programmen, aus einem Menü oder von der Befehlszeile aus aufgerufen werden. Service-Programm: Service Programme bestehen entweder aus einem einzelnen oder einem Verbund von Modulen. Die Module wiederum bestehen wiederum aus mehreren internen und exportierten Prozeduren. Die exportierten Prozeduren eines Service-Programms können aus anderen Programmen und Prozeduren aufgerufen werden. Ein direkter Aufruf, z.B. von der Befehlszeile aus ist jedoch nicht möglich. Im Gegensatz zu Programmen, werden nicht die Service-Programme, sondern die Prozeduren in den Service-Programmen aufgerufen. Während ein Programm nur einen „Program Entry Point“ hat, gibt es in Service-Programmen für jede exportierte Prozedur einen eigenen „Entry Point“.
- Binder-Verzeichnis: Verzeichnis, in das Module und Service-Programme eingetragen werden können. Binder-Verzeichnisse werden nur zur Compile-Zeit, bzw. während des Binder-Schritts verwendet, um die aufgerufenen Prozeduren in Modulen und Service-Programmen zu lokalisieren. Die gefundenen Module und Service-Programme werden anschließend in die Programm- oder Service-Programmobjekte integriert.
Mit Hilfe der ILE-Konzepte ist, im Vergleich zu der OPM-Programmierung, ein wesentlich modulareres Programm-Design möglich. Auch wenn man durch den Einsatz der ILE-Konzepte recht nah an eine objektorientiere Programmierung herankommen kann, ist und bleibt RPG (vermutlich) eine prozedurale Programmiersprache. RPG fehlen einige Features, die eine objektorientierte Programmierung erst ausmachen.
Objektorientierte Programmierung (OOP)
Bei der objektorientierten Programmierung werden Objekte mit bestimmten Eigenschaften designed. Wie das Objekt aussehen soll und durch welche Funktionen/Methoden die Eigenschaften/Daten des Objekts gesetzt werden sollen, sind in Klassen beschrieben.
Objekte werden erst zur Laufzeit generiert. Bei der Erstellung eines Objekts werden sowohl die Eigenschaften/Daten als auch die Funktionen/Methoden auf das Objekt übertragen. Auf die Daten innerhalb des Objekts kann nur mit Hilfe der integrierten Funktionen/Methoden zugegriffen werden.
Versucht man einen Vergleich mit den ILE-Konstrukten, so kann man sich ein Objekt bzw. die Eigenschaften eines Objekts als globale Datenstruktur in einem Service-Programm vorstellen. Die Daten in der globalen Datenstruktur können nur von außen, durch den Aufruf der aus dem Service-Programm exportierten Prozeduren geändert werden.
Der Unterschied zwischen OOP und ILE liegt darin, dass bei ILE jeweils nur eine einzige „Instanz“ des Objekts vorhanden ist. Ein (Service-)Programm kann innerhalb der gleichen Aktivierungsgruppe nur einmal aktiviert werden. Damit ist auch die globale Datenstruktur nur einmal vorhanden. Die rufende Prozedur muss die zurückgegebenen Daten für die weitere Verarbeitung lokal speichern.
Bei OOP dagegen kann jederzeit ein neues Objekt generiert, mit Daten versorgt und verwendet werden. Da bei OOP das Objekt immer mit den Daten und den Prozeduren identifiziert wird, können auch Techniken wie Überladung und Vererbung verwendet werden.
Überladung bedeutet, dass der gleiche Prozedur-/Funktions-/Methodenname mit unterschiedlicher Parameterdefinition in der gleichen Klasse (vergl. Service-Programm) mehrfach hinterlegt werden kann. Ebenso kann der gleiche Funktionsname für unterschiedliche Objekte verwendet werden.
In ILE-Umgebungen sollte ein Prozedur-/Funktionsname eindeutig sein. Gleiche Funktions-/Prozedurnamen sind zwar möglich, da die Prozeduren/Funktionen nicht mit dem entsprechenden Service-Programm qualifiziert werden können, kann unter Umständen die falsche Prozedur/Funktion aufgerufen und ausgeführt werden.
Sofern Prozedur-Namen mit dem Service-Programm-Namen qualifiziert werden könnten, müsste auch in ILE-Umgebungen eine Überladung möglich sein. Vielleicht wird diese Erweiterung noch irgendwann in der Zukunft in die ILE-Konzepte integriert. Aktuell kann man sich nur dadurch behelfen, dass man den Service-Programm-Namen in den Prozedur-Namen integriert.
Bei Vererbung werden Prozeduren/Funktionen/Methoden von übergeordneten Klassen übernommen und gegebenenfalls modifiziert. Diese Funktionalität wird vermutlich nie Eingang in die ILE-Konzepte finden.
Auch wenn in RPG Prozeduren und Funktionen erstellt werden können, sind diese nicht mit den Daten verknüpft und können allenfalls mit statischen Funktionen oder Methoden in einer OOP-Sprache verglichen werden.
Vergleich OPM, ILE und OOP
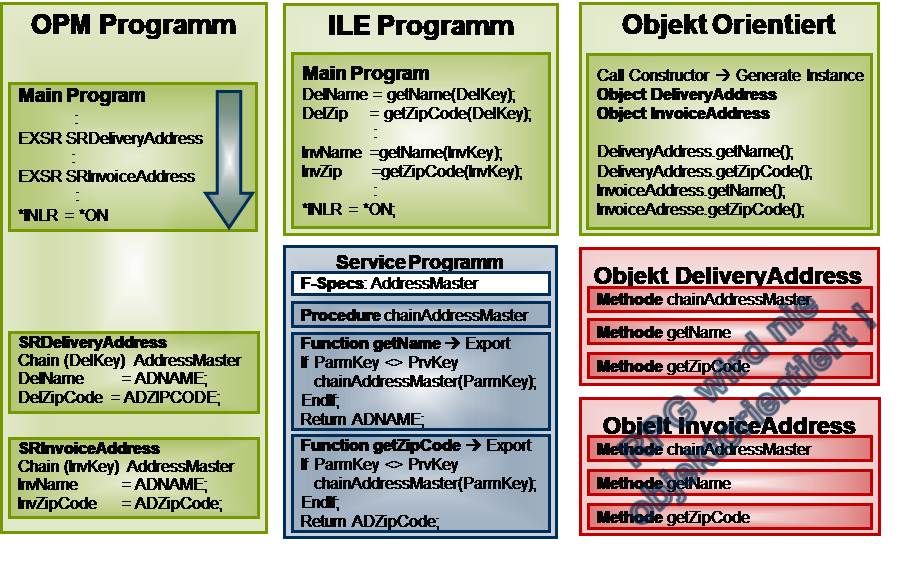 Quelle: Birgitta HauserIm Schaubild werden die verschiedenen Programmkonzepte anhand eines Beispiels verglichen. Bei der OPM-Methode auf der linken Seite wird in zwei unabhängigen Subroutinen der Adress-Stamm eingelesen, einmal für die Liefer- und einmal für die Rechnungsadresse. Der in der ersten Subroutine eingelesene Daten-Satz wird in der zweiten Subroutine überschrieben. Aus diesem Grund müssen die Liefer-/Adressdaten gerettet und in Variablen umgeladen werden.
Quelle: Birgitta HauserIm Schaubild werden die verschiedenen Programmkonzepte anhand eines Beispiels verglichen. Bei der OPM-Methode auf der linken Seite wird in zwei unabhängigen Subroutinen der Adress-Stamm eingelesen, einmal für die Liefer- und einmal für die Rechnungsadresse. Der in der ersten Subroutine eingelesene Daten-Satz wird in der zweiten Subroutine überschrieben. Aus diesem Grund müssen die Liefer-/Adressdaten gerettet und in Variablen umgeladen werden.
Werden die Liefer- und Rechnungsadresse auch in anderen Programmen benötigt, so muss der gleiche Quell-Code in die anderen Programm-Quellen übernommen werden.
Bei der ILE-Methode in der Mitte wurde der Zugriff auf den Adress-Stamm in ein eigenes Service-Programm ausgelagert. Das Service-Programm besteht aus der internen Prozedur „einlesenAdress-Stamm“, in der der gewünschte Adress-Stamm in eine globale Datenstruktur eingelesen wird. Dieser Adress-Stamm bleibt solange in den globalen Variablen erhalten, bis entweder ein anderer Daten-Satz eingelesen wird, oder die globale Datenstruktur, die den Satz hält initialisiert wird. Des Weiteren enthält das Service-Programm die beiden exportierten Funktionen „getName“ und „getPLZ“. An beide Funktionen wird der Schlüssel für den Zugriff auf den Adress-Stamm als Parameter übergeben.
Innerhalb der Funktionen wird der übergebene Schlüssel mit dem Schlüssel des aktuell eingelesenen Daten-Satzes verglichen. Sofern der Schlüssel identisch ist, wird nur entweder der Name (bei der Funktion getName) oder die Postleitzahl (bei der Funktion getPLZ) zurückgegeben, ohne dass ein erneuter Dateizugriff erfolgt. Weicht der Schlüssel ab, wird die interne Prozedur „einlesenAddressstamm“ aufgerufen. Die Übergabe der Schlüssel-Informationen ist erforderlich, da zwischen zwei Funktionsaufrufen für den gleichen Daten-Satz eine andere Funktion Daten für einen anderen Adress-Stamm angefordert haben könnte.
Im rufenden Programm ist kein Dateizugriff (mehr) hinterlegt. Die gewünschten Daten werden über Funktionsaufrufe eingelesen. Werden die gleichen Informationen auch in einem anderen Programm benötigt, müssen lediglich die Funktionsaufrufe eingebunden werden.
In diesem Beispiel wird davon ausgegangen, dass der Name und die Postleitzahl für die gleiche Adresse nacheinander ermittelt werden. Würden zunächst die Namen für beide Adressen und im Anschluss die Postleitzahlen für beide Adressen ermittelt werden, würde das Beispiel auch korrekt funktionieren, aber bei jedem Aufruf ist ein erneutes Einlesen des entsprechenden Adress-Stamms erforderlich.
Bei der OO-Methode wird zur Laufzeit für jede Adresse ein Objekt durch den Aufruf von Constructor-Methoden generiert und der entsprechende Adress-Stamm eingelesen. Auf die in den Objekten gesicherten Daten kann durch Angabe des Objekts und der gewünschten Methode direkt zugegriffen werden.
Da es sich um unabhängige Objekte handelt und die Daten, sowie die (Zugriffs-)Methoden in den Objekten integriert sind, wird der Daten-Satz für jedes Objekt einmalig eingelesen und beim Aufruf der Methoden getName und getZipCode für das entsprechende Objekt ausgegeben.
Soweit ein kurzer Überblick über die unterschiedlichen Programmier-Konzepte. In dem nächsten Artikel werden wir uns mit dem Aufbau der Quellen in einer ILE-Umgebung beschäftigen.
Birgitta Hauser
{kind=link}