
Kostenmanagement für Multicloud-Umgebungen ist eine Kunst für sich. Vielfältige Möglichkeiten stehen für die Optimierung zur Verfügung – wenn sie richtig verstanden und eingesetzt werden. Worauf es ankommt und welche Kriterien dabei wesentlich sind, klärt diese Guideline.
Rechnungs- und Nutzungsanalysen, Empfehlungen und Übersichten in Dashboards – Tools für die Cloud-Kostenoptimierung sind vorhanden und können vieles vereinfachen. Doch um Multicloud-Ökosysteme auf effiziente Weise wirtschaftlich zu steuern, braucht es eine Provider-übergreifende Sicht und Automatisierung für das Cloud-Finanzmanagement.
Um diese Möglichkeiten auch auszuschöpfen, braucht es eine Guideline für die wichtigsten Stellschrauben entwickelt. Sie zeigt, worauf Maßnahmen zur Cloud-Kostenoptimierung genau abzielen, wo die Tücken liegen und wie automatisierte Analysen wirkungsvoll eingesetzt werden.
Discount-Modelle – Puzzlespiel der Rabatte und Laufzeiten
Mit den Rabattmodellen der Provider – Reserved Instances, Savings Plans oder Committed-Use-Discounts – legt man sich auf eine bestimmte Abnahme von Cloud-Services oder Nutzung von Cloud-Instanzen für ein oder drei Jahre fest. Dafür erhält man in diesem Zeitraum für den abgeschlossenen Umfang günstigere Konditionen. Für alles darüber hinaus muss der teurere „On-Demand“-Preis bezahlt werden.
Hier gilt es, nicht in ein Over-Commitment zu verfallen, also nicht zu viel Vorab-Rabatte zu kaufen, die dann gar nicht verwendet werden. Oder der noch häufiger auftretende, umgekehrte Fall: Keine Commitments einzugehen, weil man nicht sicher vorhersagen kann, ob man dieses auch wirklich voll ausschöpfen wird. Meistens ist es günstiger, mutig einige Commitments einzugehen, auch wenn sich davon einige nicht rechnen, als gar keine einzugehen und immer den teuersten On-Demand-Preis zu zahlen.
Wer jeden Monat einige Commitments abschließt, kann auch jeden Monat deren Umfang nach oben oder nach unten anpassen. Und wer die Laufzeiten der Commitments im Blick hat, kann nahtlos weitere Vereinbarungen mit den günstigsten Preismodellen anschließen.
So sollten Tools für das Cloud-Commitment-Management zum einen in der Lage sein, anbieterübergreifend die aktuell laufenden Discount-Vereinbarungen im Unternehmen abzubilden und Vergleiche für Anschlussverträge zu unterstützen. Zum anderen sind automatisierte, rechtzeitige Benachrichtigungen an die Verantwortlichen wichtig, bevor Cloud-Commitments auslaufen.
Rightsizing – handeln, und zwar an der richtigen Stelle
Es gibt eine Reihe von Tools, die mehr oder weniger gute Vorschläge zur Dimensionierung von Cloud-Instanzen liefern, so dass sie für die tatsächliche Nutzung die richtige Größe haben. Das Problem: Jemand muss das auch umsetzen.
Praktikabel wird Rightsizing erst mit weitreichenderen Lösungen: Zuerst sollten automatisiert anhand der Cloud-Rechnungsdaten die gebuchten Cloud-Services ermittelt und diese mit Monitoring-Daten kombiniert werden. Daraus wird klar, was zu groß dimensioniert oder überhaupt nicht genutzt wurde. Dann müssen Tickets generiert werden – z.B. in Jira – mit Empfehlungen in den jeweiligen (Jira-)Projekten. So können DevOps-Teams deren Umsetzung in ihren Sprints einplanen.
Wird der Status zurück synchronisiert, ist ersichtlich, was bereits umgesetzt wurde. Idealerweise errechnet die Rightsizing-Lösung daraus die erzielten Einsparungen und welches Potential noch offen ist.
Elastizität – ausdehnen und schrumpfen, je nach Bedarf
Eine Besonderheit der Cloud im Vergleich zum Rechenzentrum ist die Elastizität. Sie ermöglicht es, aus der Analyse des Nutzungsverhaltens Cloud-Ressourcen knapp zu beauftragen und für Lastspitzen auf die Elastizität zu setzen. Dazu lohnt sich ein Austausch mit allen Beteiligten aus der Cloud-Architektur und dem Business: Wann sind hohe Spitzenlasten zu erwarten, technisch wie auch geschäftsbedingt (zum Beispiel Black Friday oder sonstige besondere Vorkommnisse).
Statt die Cloud-Infrastruktur dauerhaft für die Maximal-Last auszulegen (und dafür auch jede Minute zu bezahlen), ist es besser, die Cloud-Infrastruktur für die Grundlast auszulegen und nur bei erwarteten Spitzen Cloud-Ressourcen aufzustocken. Hier kann es sinnvoll sein, Compute-Kapazitäten vorab zu reservieren, auch genannt „Capacity Reservation“ – nicht zu verwechseln mit dem Rabattmodell „Reserved Instances“ aus vorherigem Abschnitt.
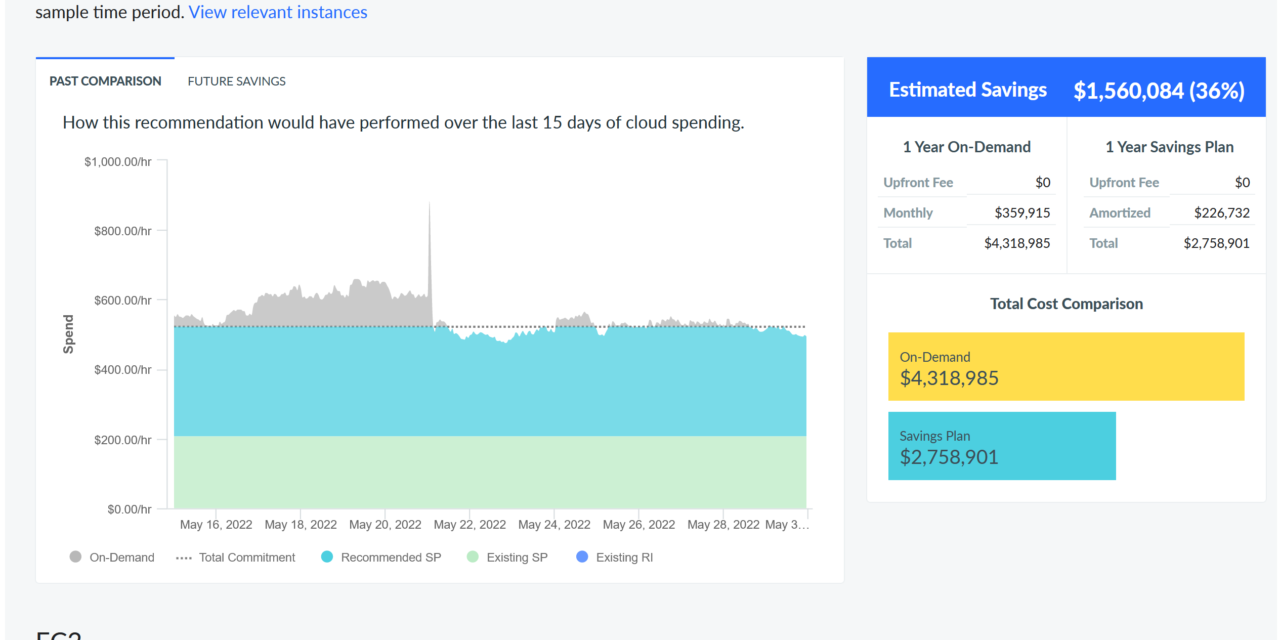
 Quelle: Apptio
Quelle: ApptioDurch die Analyse des Nutzungsverhaltens können Cloud-Ressourcen knapp beauftragt werden, um mögliche Lastspitzen über Elastizität abzudecken.
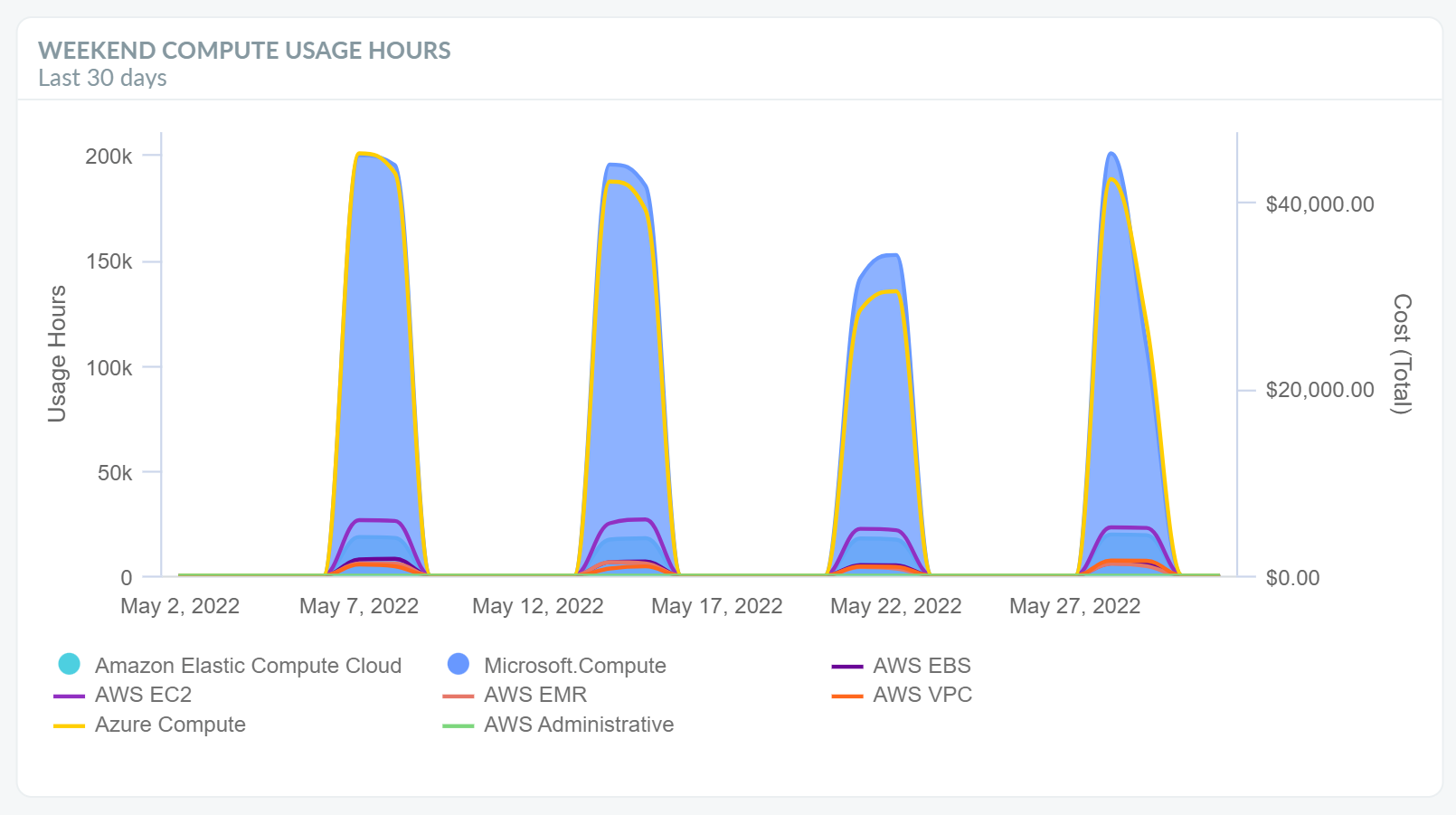
Umgekehrt können auch nicht genutzte Instanzen (zum Beispiel nicht-produktive Umgebungen am Wochenende oder in der Nacht) abgeschaltet werden und somit bis zu der Hälfte oder mehr an Kosten eingespart werden. Eine weitere Möglichkeit der Elastizität ist das Autoscaling.
Autoscaling – sparsam, aber auf alles vorbereitet
Über die Funktion Autoscaling können erforderliche Cloud-Kapazitäten anhand von vorab definierten Regeln automatisch angepasst werden. Wenn gerade wenig zu rechnen ist, genügen geringe Rechenkapazitäten, stehen rechenintensive Aufgaben an, wird Kapazität on-the-fly erhöht. Eine Autoscaling-Gruppe definiert die minimale und maximale zur Verfügung zu stellende Kapazität, welche Instanz-Typen verwendet werden sollen und wie skaliert wird.
Die Skalierung kann manuell erfolgen, zeitgesteuert oder automatisch basierend auf Applikations-spezifischen Metriken (Monitoring) und/oder anhand von Vorhersagen. Dies sorgt dafür, bedarfsorientiert und kosteneffizient die Verfügbarkeit von Services und zuverlässige Performance-Levels sicherzustellen.
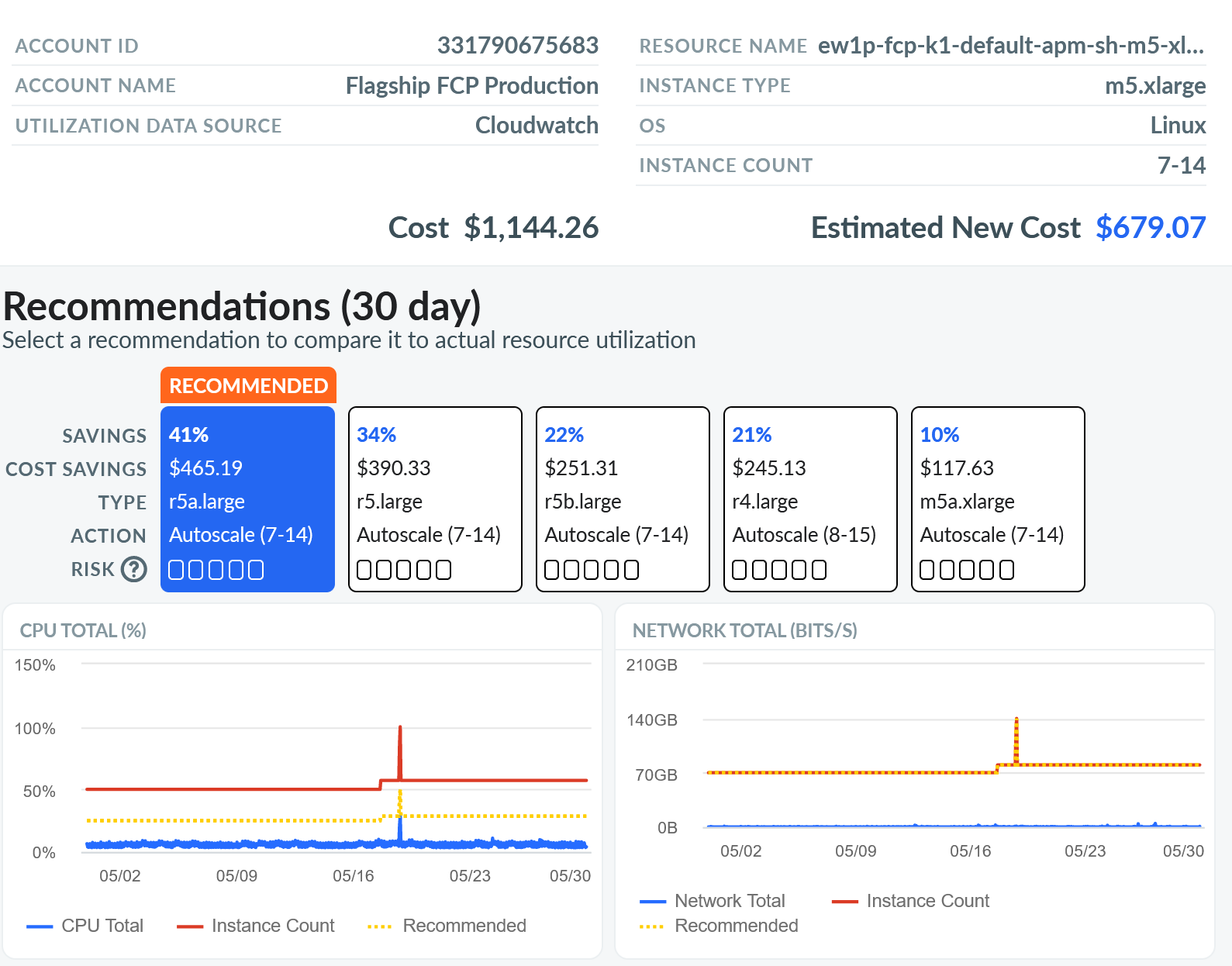 Quelle: Apptio
Quelle: ApptioPraktikables Rightsizing: Automatisierte Ermittlung der gebuchten Cloud-Services anhand der Cloud-Rechnungsdaten im Vergleich zu Monitoring-Daten macht klar, was zu groß dimensioniert oder überhaupt nicht genutzt wurde.
Obwohl moderne Architekturen meist ein Autoscaling erlauben, ist doch im Einzelfall zu klären, welche Anwendungen hierfür geeignet sind. Die Anwendung muss zumindest Load-Balancing unterstützen, so dass die Last auf mehrere Compute-Instanzen verteilt werden kann. Anwendungen, die ein stabiles und wiederkehrendes Muster im Lastaufkommen zeigen (abhängig von der Uhrzeit, dem Wochentag und/oder der Kalenderwoche), sind sehr gute Kandidaten für Autoscaling. Auto-Scaling-Gruppen können sowohl mit On-Demand-Ressourcen als auch mit Spot-Instanzen bestückt werden, siehe dazu auch den nächsten Abschnitt.
Spot Instances – lohnenswerter Zusatzaufwand
Spot-Instanzen bieten eine besonders attraktive Kostenstruktur. Allerdings sind sie nicht garantiert: Der Provider kann die Instanz jederzeit beenden, wenn er diese etwa zur Absicherung eines Workloads an anderer Stelle benötigt.
Typischerweise gibt es eine zwei-minütige Warnung, bevor die Instanz abgeschaltet wird. Es ist sozusagen eine Wette auf freie Kapazitäten in der Cloud. Damit ist klar: Das ist nicht für jede Anwendung geeignet! Wofür bieten sich Spot-Instanzen an?
- Rechenintensive Aufgaben, die jederzeit unterbrochen und wieder fortgesetzt werden können: Batch-Jobs, Compiler-Läufe oder Lernvorgänge für künstliche Intelligenz, aufwändige Video- oder Bildbearbeitungsprozesse, wissenschaftliche Berechnungen oder Simulationen, rechenintensive Finanzanalysen und Modelle
- Verteilte Datenbanken, die auch dann die Daten speichern, wenn einzelne Instanzen neu gestartet werden
- Big Data: Alle Arten der Massendatenverarbeitung
- Testing: Lasttests, Regressionstests, Sicherheitstests oder Tests mit Massendaten.
Der Lohn für den Aufwand: Spot-Instanzen sind für bis zu einem Zehntel des Preises im Vergleich zu On-Demand-Ressourcen zu haben. Da lohnen sich Tools, die die Cloud-Nutzung bezüglich Spot-, Reserved Instances, Savings Plan und On-Demand-Usage visualisieren.
Sie helfen zu verstehen, welche Workloads geeignet sind und wie die Spot Instances, die Provider nach unterschiedlichen Regelungen zur Verfügung stellen, am besten eingesetzt werden können. Wichtig ist dafür aber auch ein System für das Management unterbrochener Spot-Instance-Workloads.
Waste Management – ausmisten, aber mit Vorsicht
Im Waste-Mangement geht es darum, ungenutzte Cloud-Ressourcen zu identifizieren und unnötige Ausgaben zu vermeiden. Klingt zunächst einfach – jedoch: Welche Ressourcen tatsächlich nicht benötigt werden, lässt sich bei typischerweise mehreren hunderttausend Cloud-Ressourcen nicht manuell herausfinden.
Aus dem Vergleich von Rechnungsdaten mit Monitoring-Daten weisen Tools potenziell überflüssige Cloud-Ausgaben aus. Zudem sind unter allen hunderttausenden Cloud-Ressourcen diejenigen erkennbar, die in der Nacht oder am Wochenende nicht benötigt werden. Dabei kann auch zwischen produktiven und nicht-produktiven Umgebungen unterschieden werden.
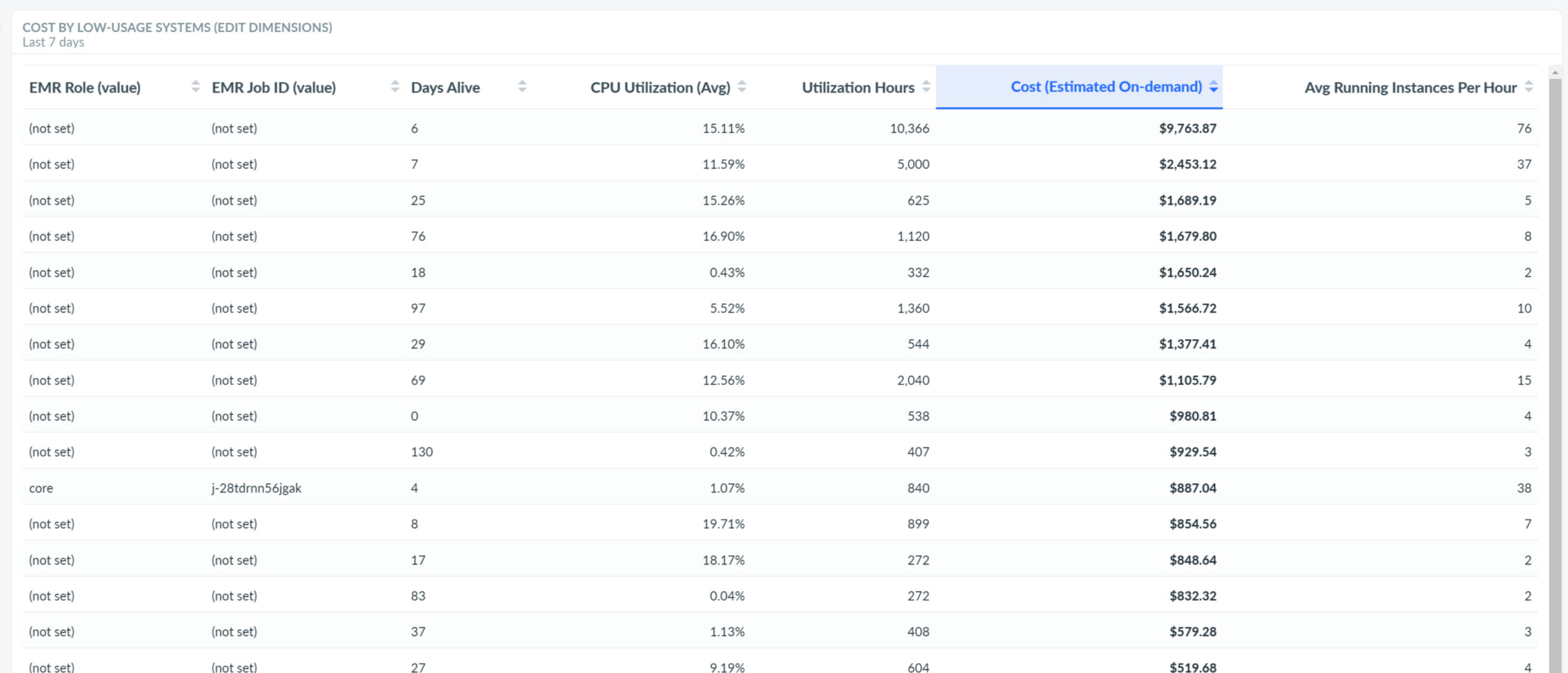 Quelle: Apptio
Quelle: ApptioAus dem Vergleich von Rechnungsdaten mit Monitoring-Daten weisen Apptio-Tools potenziell überflüssige Cloud-Ausgaben aus. Dies hilft Cloud-Architekten, abschaltbare Services aus Tausenden von Cloud-Ressourcen zu identifizieren.
Aber Achtung: Nicht oder kaum genutzte Cloud-Instanzen oder Cloud-Services sollten nicht einfach automatisch abgeschaltet, sondern Hinweise dazu in den passenden Jira-Projekten als Tickets angelegt werden. Nur die Cloud-Architekten und DevOps-Teams können fundierte Entscheidungen darüber treffen, welche Cloud-Services tatsächlich überflüssig sind und welche nicht. Selbst wenn ein Monitoring anzeigt, dass sie kaum genutzt sind – womöglich drohen Produktionsausfälle, wenn ohne nähere Kenntnis der Zusammenhänge und der Architektur einzelne Cloud-Instanzen bzw. Services nicht verfügbar sind.
Workload-Management – Vergleichbarkeit schaffen
Die Kosten für virtuelle Maschinen sind bei einzelnen Providern sehr unterschiedlich. Auch die Bezeichnung der Workloads in der Cloud, die Angebote und Konfigurationen der Cloud-Provider variieren deutlich. Dies macht es schwierig, Angebote zu vergleichen.
Doch der Preis für Workloads ist nicht der einzige Grund, sich für einen Provider zu entscheiden. Durch vorgefertigte Cloud-Services versuchen Cloud-Provider, Kunden an ihre Cloud-Plattform zu binden. Und tatsächlich ist deren Nutzung attraktiv, da sich der Provider um Wartung und Aktualisierung kümmert.
Als Entscheidungshilfe können Tools anzeigen, welche Cloud-Instanzen am ehesten zur Abdeckung eines bestimmten Workloads in Frage kommen. Meistens gibt es zwischen 40 und 50 ähnlich geartete Konfigurationen, die prinzipiell geeignet sein könnten. Wenn das Tool die Konfigurationen noch bestehender On-Premises-Server kennt, kann darüber hinaus auch ermittelt werden, durch welche Cloud-Instanzen sie ersetzt werden könnten. Dies ermöglicht Vergleiche, welche Cloud-Angebote am besten geeignet sind – auch, aber nicht nur bezüglich des Preis-/Leistungsverhältnisses.
Transparenz schafft verantwortungsvollen Umgang
Wichtig ist: Neben allen Cloud-Kosten-Optimierungen braucht es einen verantwortungsvollen Umgang mit Ressourcen in der Cloud. Im ersten Schritt wird das dafür nötige Verantwortungsbewusstsein durch Kostentransparenz und verursacher-gerechte Zuordnung geschaffen. Die Teams müssen verstehen, welche Kosten sie durch ihre Art der Cloud-Nutzung verursachen und was die Kern-Kostentreiber sind. Im zweiten Schritt kann man die Kosten nicht nur aufzeigen, sondern auch über eine interne Kostenverrechnung den Teams in Rechnung stellen.
Wenn eine kosteneffektive Nutzung der Cloud mit zu den Zielen zählt, werden die Cloud-Kosten nicht mehr ungebremst steigen, sondern dort in Cloud-Services investiert, wo der Business-Nutzen die Ausgaben rechtfertigt.
Die Erfolgsbewertung von Cloud-First-Strategien ist erheblich von den Public-Cloud-Kosten beeinflusst. Sie immer besser zu verstehen und das Cloud-Financial-Management mehr und mehr direkt auch in den DevOps-Teams zu verankern ist ein wichtiger Prozess. Denn ihre Expertise ist entscheidend, um mit Cloud-Infrastrukturen nicht nur ein zuverlässiges, sondern auch wirtschaftlich tragfähiges Modell für das operative Geschäft zu schaffen.
Thomas Köppner ist Solution Consultant bei Apptio.
{kind=link}