

OmniFind ist eine Plattform für die Suche in unstrukturierten Texten innerhalb oder außerhalb der DB2 in Dokumenten im integrierten File-System, in Spoolfiles und in Source Physical Files.
Es ist eine interessante Möglichkeit von OmniFind, auf Daten zuzugreifen, die sich im IFS befinden. Auf diese Weise kann eine Suche in Handbüchern realisiert werden, die als PDF-Dokumente vorliegen. Eine weitere Anwendung ist die Verbindung von Daten in der Datenbank mit IFS-Dokumenten.
 Quelle: Rainer Ross
Quelle: Rainer RossBild 1. Handbücher im Verzeichnis /tmp/Manuals im PDF-Format
Ein Anwendungsfall ist die Verknüpfung von Personaldaten aus der Datenbank mit den Lebensläufen, die als PDF oder Word-Dokument gespeichert sind. Es ist ebenso möglich, Kundendaten und Besuchsberichte oder Artikeldaten mit QS-Berichten zu verknüpfen. Voraussetzung ist die Zuordnung des IFS-Dokuments zum Schlüssel in der DB2-Tabelle.
Im folgenden Beispiel geht es um die Indexierung von IFS-Dokumenten. In diesem Fall handelt es sich um IBM-Handbücher, die als PDF-Dokumente vorliegen. Im Verzeichnis /tmp/Manuals sind Dokumente vorhanden, wie sie in Bild 1 gezeigt sind.
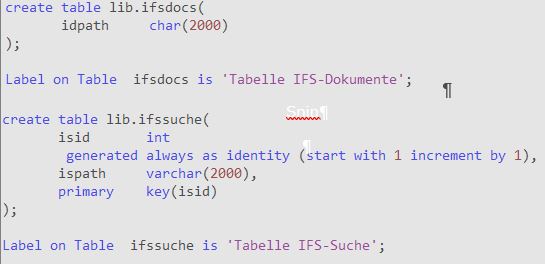
Bild 2. Erstellen der Tabellen IFSDOCS und IFSSUCHE
Zuerst werden zwei Tabellen erstellt, die die Pfadeinträge enthalten (code siehe Bild 2). Anstelle von „lib“ geben Sie bitte Ihren eigenen Bibliotheksnamen an.
Dabei ist allerdings Vorsicht geboten: Das Laden der Dokumentinhalte geschieht mit der SQL-Funktion GET_BLOB_FROM_FILE(Pfadname). Der Pfadname darf keine Blanks enthalten. Deshalb ist das Feld ISPATH in der Tabelle IFSSUCHE mit variabler Länge definiert.
Das Lesen der Dokumente geschieht mit dem Qshell-Befehl
„find <Pfad> -type f“
, der über ein CL aufgerufen wird und den Inhalt des Verzeichnisses in die Tabelle IFSDOCS schreibt. Die Option „-type f“ listet nur File-Namen auf und keine Verzeichnisse (siehe Bild 3).
 Quelle: Rainer Ross
Quelle: Rainer RossBild 3. CL zum Auslesen eines IFS-Verzeichnisses und Schreiben der Ergebnisse in die Tabelle IFSDOCS
Mit der folgenden SQL-Anweisung werden Daten in die Tabelle IFSSUCHE kopiert:
insert into ifssuche (ispath) select trim(idpath) from ifsdocs;
Mit dem folgenden SQL-Statement wird der Suchindex erstellt:
Call sysproc.systs_create(
‘lib‘,
‘ifsindex‘,
‘lib.ifssuche(get_blob_from_file(ispath))‘,
‘format inso‘
);
Die Aktualisierung des Suchindexes geschieht mit dem SQL-Statement:
call sysproc.systs_update(‘lib‘, ‘ifsindex‘, ‘using update minimum‘);
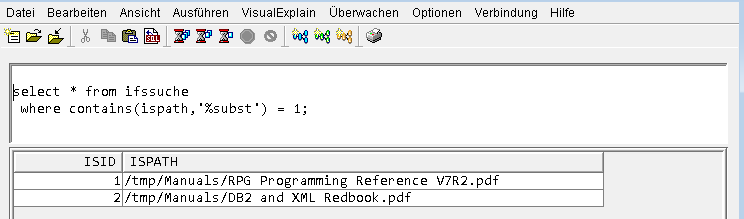
Jetzt können Abfragen auf den Inhalt der Handbücher durchgeführt werden. Als Erstes wird nach der RPG-Funktion „%subst“ gesucht (siehe Bild 4).
 Quelle: Rainer Ross
Quelle: Rainer RossBild 4. Suche nach „%subst“ in indexierten PDF-Handbücher;
Das nächste Beispiel sucht nach den Handbüchern, in denen die Begriffe „create“ und „table“ vorkommen.
 Quelle: Rainer Ross
Quelle: Rainer RossBild 5. Suche nach „create“ und „table“ in indexierten PDF-Handbüchern
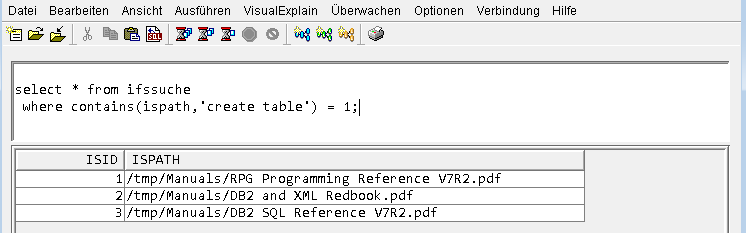
Mit diesem Beispiel wird nach dem Begriff „create table“ gesucht.
Bitte beachten Sie, dass für die exakte Suche der Begriff in doppelte Hochkommas gesetzt werden muss:
 Quelle: Rainer Ross
Quelle: Rainer RossBild 6.Exakte Suche nach „create table“ in indexierten PDF-Handbüchern
Textsuchgruppen
Eine Neuerung in V7R1 sind Textsuchgruppen. Sie werden verwendet, um Daten zu indexieren, die sich außerhalb der DB2 befinden:
- Spool-Daten,
- Daten im Integrated File System – IFS,
- physische Quellendateien mit mehreren Teildateien-Source Physical Files.
Ein praktischer Anwendungsfall ist das Erstellen einer Textsuchgruppe, die alle Sourcen eines Projekts oder alle Sourcen der IT-Abteilung enthält. Somit können auf einfache Weise und sehr schnell die Sourcen nach vorgegebenen Suchkriterien durchsucht werden.
Beispiel: Es werden alle Programmsourcen benötigt, die die Dateien „Kunden“ und „Artikel“ enthalten, nicht aber die Datei „Vertreter“.
call sourcen.search(‘kunden artikel -vertreter‘);
Textsuchgruppe für Source Physical Files erstellen
Die Textsuchgruppe wird mit dem SQL-Befehl SYSTS_CREATE_COLLECTION erstellt. Im folgenden Beispiel wird die Textsuchgruppe „Sourcen“ erstellt, die Quellen aus verschiedenen Bibliotheken enthalten soll:
CALL SYSTS_CREATE_COLLECTION(‘sourcen‘);
Der Befehl erstellt die Bibliothek „SOURCEN“, die folgende Objekte enthält:
- Kataloge zum Aufzeichnen der Konfiguration der Objektgruppe,
- Kataloge zum Aufzeichnen der indexierten Objekte,
- gespeicherte SQL-Prozeduren zum Verwalten und Durchsuchen der Objektgruppe.
SYSTS_CREATE_COLLECTION wird mit der Berechtigung *EXECUTE ausgeliefert. Damit der Aufrufer den Befehl ausführen kann, muss er über Folgendes verfügen:
- Berechtigung zum Erstellen eines DB2-Schemas,
- Berechtigung zum Erstellen eines Textsuchindexes.
Nachdem die Textsuchgruppe erstellt worden ist, können mit dem SQL-Befehl ADD_SRCPF_OBJECT_SET die Source Physical Files hinzugefügt werden.
CALL sourcen.ADD_SRCPF_OBJECT_SET(‘TSTS‘,‘ALLSRCPF‘);
CALL sourcen.ADD_SRCPF_OBJECT_SET(‘DEVS‘,‘QDDSSRC‘);
CALL sourcen.ADD_SRCPF_OBJECT_SET(‘TOOL‘,‘QRPGSRC‘);
Mit der Option *ALLSRCPF werden automatisch alle Source Physical Files einer Bibliothek dem Textsuchindex hinzugefügt.
Das Löschen eines Eintrags in die Textsuchgruppe geschieht mit dem Befehl RMV_SRCPF_OBJECT_SET oder mit REMOVE_OBJECT_SET.
QUERY_OBJECT_SET gibt den Inhalt und den Status der Textsuchgruppe aus. Da die Sourcen noch nicht indexiert sind, ist das Feld LASTREFRESHTIME noch leer.
Der Aufruf
call sourcen.QUERY_OBJECT_SET;
ergibt eine Inhaltsanzeige, wie sie in Bild 7 zu sehen ist.
 Quelle: Rainer Ross
Quelle: Rainer RossBild 7. Inhaltsanzeige der Textsuchgruppe „Sourcen“ mit QUERY_OBJECT_SET
Eine Suche ist jetzt noch nicht möglich. Mit dem SQL-Befehl UPDATE wird der Suchindex aufgebaut:
call sourcen.update;
Der QUERY_OBJECT_SET führt jetzt zu dem Ergebnis, das in Bild 8 zu sehen ist.
 Quelle: Rainer Ross
Quelle: Rainer RossBild 8. Inhalt der Textsuchgruppe „Sourcen“ mit QUERY_OBJECT_SET
Das Feld LASTREFRESHTIME enthält nun den Zeitstempel der letzten Aktualisierung des Textindexes.
Jetzt kann in den Sourcen der Textsuchgruppe gesucht werden, z. B. alle Sourcen, die im Header NOMAIN enthalten, den Befehl %SCANRPL verwenden, aber nicht das Feld h#html enthalten dürfen:
call sourcen.search(‘nomain %scanrpl -h#html‘);
Die Suche liefert folgendes Ergebnis: Die Ergebnisse werden nach Score absteigend sortiert (siehe Bild 9).
Die Ergebnisspalten des Suchergebnisses sehen wie aus, wie sie in der Tabelle 1 gezeigt sind.
 Quelle: Rainer Ross
Quelle: Rainer RossTabelle 1
Dabei steht
OBJTYPE: Der Objekttyp des Ergebnisses. In diesem Fall *SRCPF.
OBJATTR: Das Objektattribut des Ergebnisses. Hier ist es das *MBR eines *SRCPF.
CONTAINING_OBJECT_LIB: Die Bibliothek, die das Suchergebnis enthält.
CONTAINING_OBJECT_NAME: Der Objektname des Source Physical File.
OBJECTINFOR: Ein XML-String, der die Bibliothek, die SRCPF und den Member-Namen enthält.
 Quelle: Rainer Ross
Quelle: Rainer RossSuchergebnisse
Der String hat folgendes Format:
<Source_Physical_File_Member
xmlns=”http://www.ibm.com/xmlns/prod/db2textsearch/obj1>
<file_library>MYLIB</file_library>
<file_name>MYPF</file_name>
<member_name>teildatei1</member_name>
</Source_Physical_File_Member>
MODIFY_TIME: Der Zeitpunkt der letzten Änderung.
SCORE: Ein Wert zwischen 0 und 1, der darüber Auskunft gibt, wie oft der Suchausdruck im Suchergebnis vorhanden ist. Je höher dieser Wert ist, umso öfter wurde eine Übereinstimmung mit den Suchkriterien gefunden.
Eine Textsuchgruppe kann IFS-Daten, Spool-Daten und Source-Physical-File-Daten enthalten. Es ist ebenso möglich, jeweils eine Textsuchgruppe zu erstellen, die nur IFS- oder SRCPF-Daten enthält.
Rainer Ross
{kind=link}