


Physische und logische Dateien werden auf der Basis einer DDS-Beschreibung durch die CL-Befehle CRTPF (physische Datei erstellen) bzw. (logische Datei erstellen) generiert. SQL-definierte Tabellen, Views und Indices werden über die SQL-Befehle CREATE TABLE, CREATE VIEW und CREATE INDEX erstellt. Bei Änderung von DDS-beschriebenen Dateien wird zunächst der DDS-Code geändert und dann die Datei über CRTPF bzw. CRTLF neu erstellt oder mittels CHGPF (Physische Datei ändern) geändert. Bei SQL-Tabellen erfolgt eine Änderung mit Hilfe des ALTER TABLE-Statements. Zumindest war dies bis Release 7.2 Technology Refresh (TR 1) der Fall. Dann wurde der CREATE TABLE-Befehl um die Angabe OR REPLACE erweitert. In diesem Artikel werden die Möglichkeiten, die der CREATE OR REPLACE-Befehl bietet aufgezeigt und demonstriert, wie er beim Konvertieren von DDS-beschriebenen Dateien in SQL-Datenbanken-Objekte genutzt werden kann.
Bevor wir uns den CREATE OR REPLACE Table im Detail anschauen zunächst eine kurze Zusammenfassung zu Erstellung und Änderung von DDS beschriebenen Dateien. Die Verwaltung von DDS-beschriebenen Dateien erfolgt in mehreren Schritten. Für neue DDS-beschriebene Dateien wird zunächst der DDS-Quell-Code erstellt und in einer Quellen-Teildatei mit Datei-Art PF (physische Datei) oder LF (logische Datei) angelegt.
Erstellen von DDS-beschriebenen Dateien
Mit Hilfe der CL-Befehle CRTPF (physische Datei erstellen) und CRTLF (logische Datei erstellen) werden die Datenbanken-Objekte aus dem Quell-Code generiert.
Änderung/Erweiterung von DDS-beschriebenen Dateien
Sofern eine DDS-beschriebene Datei geändert werden muss, wird zunächst der DDS-Quell-Code angepasst. Logische Dateien können im Anschluss an die Änderung direkt neu erstellt werden.
Bei physischen Dateien, kann eine erneute Erstellung nicht durchgeführt werden, solange noch abhängige Datenbanken-Objekte (z.B. logische Dateien) mit der physischen Datei verlinkt sind. Wird eine physische Datei ohne abhängige Objekte, neu erstellt, werden die Daten nicht übernommen. Das heißt also, Daten müssen zunächst gesichert und im Anschluss daran in die neue Datei übernommen werden.
Damit war eine Datei-Erweiterung von DDS-beschriebenen Dateien ein ziemlich aufwändiges Geschäft. Zumindest dann, wenn man die zuvor genannten Schritte, also abhängige Objekte löschen, Daten sichern, Datei erstellen, Daten in die neue Datei einfügen, abhängige Objekte neu erstellen, manuell ausgeführt hat. Setzt man allerdings den CL-Befehl CHGPF (Physische Datei ändern), kann man die physische Datei in einem Schritt erweitern. Daten und abhängige Objekte bleiben erhalten.
Vorteile von DDS-beschriebenen physischen Dateien gegenüber SQL-Tabellen
Die Erstellung und Verwaltung von DDS-beschriebenen physischen Dateien hatte lange Zeit, genauer gesagt bis Release 7.2 TR 1 gegenüber der Verwaltung von SQL-Tabellen einige vielfach entscheidende Vorteile:
• Bei DDS-beschriebenen physischen Dateien, muss zunächst der Source-Code erstellt und geändert werden, bevor die Datei erzeugt wird. Bei SQL-definierten Datenbanken-Objekten wird das Objekt direkt über einen Erstellungsbefehl generiert. Eine Sicherung des Erstellungsbefehls ist nicht zwangsläufig erforderlich, da der Erstellungsbefehl jederzeit über Reverse Engineering generiert und ggf. geändert bzw. erweitert werden kann.
• Bei DDS-beschriebenen physischen Dateien können neue Spalten an jeder Position innerhalb der Datei eingefügt werden. Bei SQL-definierten Tabellen können Spalten mit Hilfe des ALTER TABLE-Befehls hinzugefügt oder geändert werden. Bis vor Release 6.1 konnten neue Spalten nur ans Ende der Spalten-Liste angefügt werden. Seit Release 6.1 ist es möglich mit Hilfe der Angabe BEFORE SPALTENNAME eine neue Spalte an jeder Stelle der Spalten-Liste zu integrieren.
• Bei DDS beschriebenen Dateien, konnten Felder basierend auf Felder aus einer Feld-Referenz-Datei definiert werden. Bei Änderung von Feldern in der Feld-Referenz-Datei, mussten die Dateien in denen die Referenz-Felder verwendet wurden, lediglich durch den Befehl CHGPF angepasst werden. SQL unterstützt nicht direkt die Verwendung von Feld-Referenz-Dateien. Seit Release V5R1M0 ist es zwar möglich Tabellen basierend auf einem SELECT-Statement zu erstellten, abgespeichert werden allerdings nur die absoluten Spalten-Definitionen. Der Bezug zur Referenz-Datei geht verloren. Bis vor Release 7.2 TR 1 konnten Erweiterungen in der Referenz-Datei nur durch gezielte ALTER TABLE-Statements für jede Tabelle bzw. jede Spalte mit Referenz auf die geänderte Spalte erreicht werden.
CREATE OR REPLACE TABLE
Mit der Erweiterung CREATE OR REPLACE TABLE ist es möglich den Erstellungsbefehl für eine Tabelle zu ändern, d.h. eine Spalte an einer beliebigen Stelle einzufügen, die Definition von vorhandenen Spalten zu ändern und sogar Tabellen mit Spalten-Definitionen basierend auf einer Referenz-Datei zu verwalten.
Das geänderte CREATE OR REPLACE-Statement wird nach der Änderung lediglich erneut ausgeführt. Die in der Tabelle bereits vorhandenen Daten werden beibehalten und ggf. in einen anderen Datentypen konvertiert (z.B. von Datentyp VARCHAR nach VARGRAPHIC oder von INTEGER nach DECIMAL). Abhängige Objekte, wie Views, Indices und Trigger bleiben ebenfalls erhalten und werden ggf. entsprechend angepasst.
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserDie Änderung CREATE OR REPLACE TABLE wurde mit Release 7.2 TR 1 eingeführt über PTFs jedoch auch für die Release 6.1 und 7.1 bereitgestellt. Die Änderungen im CREATE OR REPLACE TABLE-Befehl werden im Untergrund in eine Reihe von ALTER TABLE Statements übersetzt. Das bedeutet, dass der Befehl CREATE OR REPLACE TABLE nur das unterstützt, was auch durch den Befehl ALTER TABLE unterstützt wird.
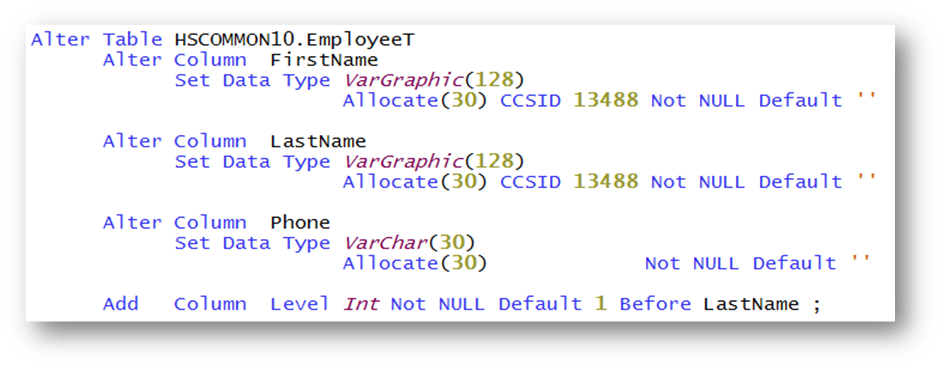
Anstatt also eine Reihe von ALTER TABLE-Statements auszuführen, ist nur noch ein einziges CREATE OR REPLACE TABLE-Statement erforderlich. Das folgende Beispiel zeigt zunächst ein ALTER TABLE-Statement, über das die Spalten FIRSTNAME, LASTNAME von 50 auf 128 Zeichen erweitert werden und außerdem vom Datentypen VarChar auf VarGrahpic mit CCSID 13488 (UCS2) konvertiert werden. Des Weiteren wird die Telefon-Nr., Spalte PHONE von 15 Zeichen auf 30 Zeichen erweitert. Zum Schluss wird noch eine neue Spalte, LEVEL vor die Spalte LASTNAME eingefügt.
Das nächste Statement zeigt die Änderung mit Hilfe des CREATE OR REPLACE TABLE-Statements. Anstatt die Spalten einzeln zu erweitern wurde das ursprüngliche Erstellungsstatement modifiziert. Die Spalten-Definitionen wurden auf die neuen Datentypen und Längen geändert.
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserDie Spalte Level wurde in das SQL-Skript unmittelbar nach der Definition der Spalte EmployeeNo eingefügt. Die ursprünglichen Spalten-Definitionen wurde in diesem Beispiel lediglich auskommentiert. Wird das SQL-Skript ausgeführt werden die geänderten Spalten angepasst und die Spalte Level im Anschluss an die Spalte EmployeeNo eingefügt.
Von DDS nach SQL
Mit Reverse Engineering kann das SQL-Statement zur Erstellung des Datenbanken-Objekts generiert werden. Das gilt auch für DDS-beschriebene Dateien. In dem letzten Artikel dieser Reihe wurde bereits das SQL-Skript für die DDS-beschriebene Datei SALESP erzeugt. Das SQL Skript enthält einige Kommentare, über Features, die in SQL-beschriebenen Tabellen entweder nicht unterstützt oder per Default anders eingesetzt werden.
So werden SQL-beschriebene Tabellen mit der Option REUSEDLT(*YES) erstellt. Wird ein Datensatz gelöscht, wird dieser zunächst als gelöscht gekennzeichnet, jedoch nicht physisch aus der Tabelle entfernt. Wird ein neuer Datensatz eingefügt, wird zunächst geprüft, ob ein als gelöscht gekennzeichneter Datensatz vorhanden ist. Wird ein als gelöscht gekennzeichneter Datensatz gefunden, wird dieser mit dem neuen Datensatz überschrieben.
Mit DDS beschriebene Dateien werden per Default mit REUSEDLT(*NO) erstellt. Auch bei DDS-beschriebenen Dateien werden Datensätze nicht physisch gelöscht, sondern lediglich als gelöscht gekennzeichnet. Beim Einfügen von neuen Datensätzen werden jedoch die als gelöscht gekennzeichneten Datensätze ignoriert und jeweils ein neuer Datensatz ans Ende der Datei angefügt.
Als gelöschte gekennzeichnete Datensätze werden sowohl bei DDS beschriebenen Dateien als auch SQL-definierten Tabellen werden nur durch Ausführung des CL-Befehl RGZPFM (Physische Datei reorganisieren) physisch aus der Datei entfernt.
Da in unserem Beispiel die Position bzw. die Reihenfolge der Datensätze für die Programm-Ausführungen unwichtig ist, spielt es auch keine Rolle, ob die Tabelle mit REUSEDLT *YES oder *NO generiert wird. Der Kommentar kann also ignoriert werden.
Für die ursprüngliche DDS-beschriebene Datei ist ein Zugriffs-Schlüssel definiert. SQL-Tabellen können dagegen nicht mit integriertem Schlüssel generiert werden. Deshalb wurde zusätzlich der Source-Code für einen separaten SQL-Index generiert.
Sofern es Programme oder Prozeduren gibt, in denen geschlüsselte Zugriffe auf die DDS-beschriebene physische Datei erfolgen, müssen vor der Konvertierung von DDS auf SQL zunächst Programme und Prozeduren angepasst werden. Anstatt auf die physische Datei müssen die native I/O-Zugriffe nun auf den neuen Index oder einen anderen Index (oder logische Datei) mit der entsprechenden Schlüsselung erfolgen.
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserDabei darf man aber eines nicht vergessen: Erstellt man für den integrierten Schlüssel einen Primary Key, so kann auch auf die SQL Tabelle über Schlüssel zugegriffen werden. Da zu einem Zeitpunkt in der Zukunft die Datenbank bzw. die Tabellen redesignet werden sollen, und dann auch referentielle Integritäten eingerichtet werden sollen, ist ein zusätzlicher Index die bessere Wahl. Nachdem die Zugriffe über native I/O auf den zusätzlichen Index umgestellt wurden, kann die eigentliche Umstellung erfolgen.
In unserem Beispiel wird allerdings noch eine Erweiterung vorgenommen. Da man zukünftig von den kryptischen, maximal 10-stelligen System-Spalten-Namen auf längere sprechende SQL-Namen umstellen möchte, wurden in das SQL-Skript zusätzlich lange sprechende SQL Namen hinzugefügt.
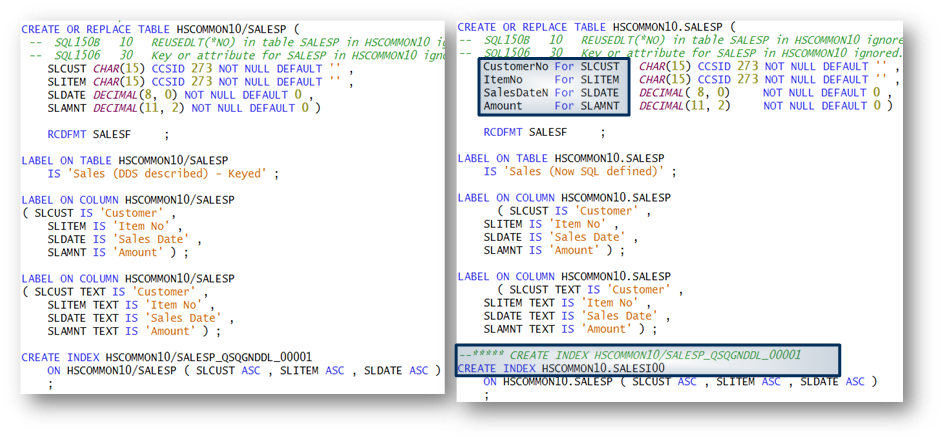
Das Bild 3 zeigt den über Reverse-Engineering generierten SQL-Code auf der linken Seite und den modifizierten SQL-Code auf der rechten Seite.
Führt man das modifizierte SQL-Skript aus wird die vorhandene DDS-beschriebene Datei in eine SQL-Tabelle konvertiert und zusätzlich zu den kurzen System-Namen die langen SQL-Namen eingefügt. Daten und abhängige Objekte bleiben erhalten. Durch die folgenden Abbildungen kann diese Behauptung bestätigt werden.
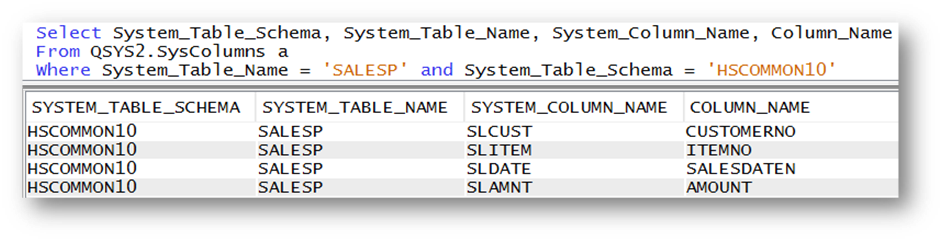
Das folgende SELECT-Statement liefert Tabellen Informationen nach der Konvertierung der Tabelle SALESP aus der Catalog-View SYSTABLES. Der Tabellen-Typ ist nicht länger P (= physische Datei) sondern T (= Tabelle).
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserSieht man sich nun die Spalten-Beschreibung der Tabelle mit Hilfe der Catalog View SYSCOLMNS an, stellt man fest, dass die ursprünglichen kurzen Spalten-Namen als System-Namen verwendet werden, und die im Skript angegeben langen Namen als Spalten-Namen übernommen wurden (Bild 5.).
Werden nach der Konvertierung der DDS-beschriebenen Datei in die SQL-Tabelle die Programme und Prozeduren mit native I/O aufgerufen, so werden diese problemlos ausgeführt. Eine (Re-)Kompilierung der Programme und Module ist nicht erforderlich.
Rufen wir jetzt unser Beispiel-Programm auf, entweder aus einem neuen Job oder aus dem gleichen Job nach dem Schließen der Aktivierungsgruppe SALESP02 über den CL-Befehl RCLACTGRP (Aktivierungsgruppe zurückfordern), kann das Programm problemlos ausgeführt werden.
Nach der Konvertierung auf SQL-Tabellen können bei zukünftigen Datei-Erweiterungen oder -Änderungen alle nur für SQL-Tabellen hinzugefügten Neuerungen eingesetzt werden.
Konvertierung wird weiter getrieben
 Quelle: Birgitta Hauser
Quelle: Birgitta HauserSoweit zu Konvertierung von DDS beschriebenen physischen Dateien auf SQL definierte Tabellen. Im nächsten Artikel werden wir uns mit der Konvertierung von logischen Dateien in SQL Indices beschäftigen. Und nun viel Spaß bei der Konvertierung von physischen Dateien in SQL-Tabellen.
Birgitta Hauser