
Die Technologie „Persistent Memory“ (PMEM) verspricht ein enormes Potenzial speziell für die Optimierung von In-Memory-Datenbanken wie SAP HANA. Doch trotz aller Euphorie sollte eine nüchterne Bewertung angewandt werden – es reicht nicht, nur die schnelleren Startzeiten für die Datenbank zu preisen. Es geht mehr um die Verbesserungen, die sich im „Normalbetrieb“ damit realisieren lassen.
Speziell Datenbanken, die auf dem Prinzip „In Memory“ basieren, haben ein Problem, wenn die Stromversorgung für den Arbeitsspeicher – also das DRAM – aus welchen Gründen auch immer ausfällt: Die aktuellen Informationen sind erst einmal weg. Mit vergleichsweise aufwendigen Techniken muss dann versucht werden, eine Wiederherstellung des aktuellen Betriebszustands der Datenbank zu erreichen, ohne dass eine Transaktion dabei verloren geht.
Wenn es nun einen schnellen Arbeitsspeicher geben würde, der Informationen auch noch bei einem Ausfall der Stromversorgung gespeichert behielte – wenn also aus einem flüchtigen Speicher ein „persistenter Speicher“ werden könnte, dann wäre das Problem gelöst.
Persistent Memory für SAP HANA
Beim Persistent Memory (PMEM) handelt es sich um so etwas wie Hauptspeicher, bei dem aber die Informationen auch nach einem Abschalten des Systems oder bei einem Stromausfall erhalten bleiben. Das klingt super und ist es auch. In Bezug auf die Datenbank SAP HANA lassen sich so einige Verbesserungen erzielen (siehe Grafik PMEM und SAP HANA):
- Beim Start eines HANA-basierten Systems entfällt das Laden der Tabellen, da der „Column Store“ bereits im Persistent Memory liegt. Die „volatilen“ Strukturen wie der Delta Store und andere müssen dennoch im Memory aufgebaut werden.
- Es lassen sich kostengünstigere Speicherlösungen verwenden, da DRAM teurer ist als die neuen PMEM-Module.
- In den Systemen steht mehr „Hauptspeicher“ zur Verfügung, da statt DRAM-DIMMs nun „größere“ PMEM-DIMMs verwendet werden können.
Diese Vorteile haben Auswirkungen auf die Performance eines HANA-Systems: Der Start von HANA kann nun schneller erfolgen (SAP spricht in einem Blog-Beitrag vom Faktor 12,5: blogs.sap.com/2018/12/03/sap-hana-persistent-memory/). Doch ausschlaggebend ist nicht allein das Starten des Systems, es sollte vor allem der laufende Betrieb im Vergleich zu traditionellem DRAM untersucht werden. Denn bei SPS 04 für HANA 2.0 ist eine Fast Restart Option enthalten. Sie hat zur Folge, dass bei einem Neustart von HANA die Daten ebenfalls erhalten bleiben – auch ohne den Einsatz von PMEM.
Bei dem im SAP-Blog angeführten Vergleich eines schnelleren Systemstarts mit PMEM gegenüber einem Systemstart nur mit DRAM sollte man auch die „Testumgebung“ genau betrachten: Dabei kommt relativ wenig Hauptspeicher zum Einsatz sowie eine Datenbank, die komplett in den PMEM-Bereich passt. Danach vergleicht man das System, das „nur Hauptspeicher“ enthält, mit dem System, das die gleiche Menge Hauptspeicher plus genügend Persistent-Memory-Module für die Testdatenbank enthält. Dass die Performance des Systems mit zusätzlichen PMEM-Modulen schneller ist, ist keine große Überraschung. Es stellt sich jedoch die Frage, wie groß der Performance-Unterschied ausfallen würde, wenn das Vergleichssystem die maximale Anzahl von DIMMs enthalten hätte, wenn ein geeignetes Sizing im Vorfeld vorgenommen worden wäre oder zusätzlich eine höhere Bandbreite zur Verfügung stünde.
Eine Untersuchung der University of California (siehe www.arxiv.org/pdf/1903.05714.pdf) hat die Performance eines PMEM-Systems untersucht. Dabei wurde festgestellt, dass PMEM beinahe so schnell im „sequentiellen Lesen“ sein kann wie DRAM, aber bezüglich „zufälligem Schreiben“ (Random Write) schnell an Performance verliert.
Diese Charakteristik spielt zum Beispiel im Business Warehouse-Umfeld eine weniger relevante Rolle. Allerdings stellt sich die Frage, wie viel an Performance-Verlust man bei ERP-Anwendungen mit vielen „Delta Merges“ bei hohen Transaktionsraten in Kauf nehmen muss.
Das zweite Argument für PMEM, das Thema „Kosten des Arbeitsspeichers“, sollte immer auch im Kontext von Performance-Klassen erfolgen. Lässt man diesen Faktor außen vor und fokussiert sich nur auf die Memory-Preise sowie die Optionen für den Einsatz von PMEM, ergibt sich folgendes Bild:
Jeder Sockel eines Intel-basierten Systems bietet 12 DIMM-Steckplätze. Zu jedem PMEM-Modul muss laut Hersteller auch ein DRAM DIMM zusätzlich gesteckt werden, der als eine Art Cache für PMEM eingesetzt wird. Da die PMEM-Module größer sein können als die DRAM DIMMs, steht mehr Hauptspeicher zur Verfügung: Für ein Intel-Zweisockelsystem bedeutet dies, dass statt maximal 3 TByte DRAM (24 × 128 GByte) nun bis zu 7,5 TByte (12 × 128 GByte DRAM plus 12 × 512 GByte PMEM) durch den Einsatz von PMEM installiert werden können.
Folgt man allerdings den üblichen HANA-Sizing-Regeln, dass man gegenüber dem Column Store doppelt so großen Hauptspeicher einsetzen sollte, benötigt man letztendlich auch mindestens so viel DRAM, wie für den Column Store notwendig ist. Nimmt man preislich an, dass PMEM etwa halb so teuer wie DRAM ist, würde man letztendlich etwa 25 Prozent der Kosten für „Hauptspeicher“ sparen – allerdings für ein System mit geringerer Performance. Jedoch ist noch ein Faktor zu beachten: Die Prozessoren, die für den Einsatz von PMEM verwendet werden können, sind teurer.
Bisher unbefriedigend geklärt sind meines Erachtens Fragen zu Zuverlässigkeit und Verfügbarkeit von PMEM.
Weitere Quellen zum Thema:
blogs.sap.com/2018/12/03/sap-hana-persistent-memory/
www.researcher.watson.ibm.com/researcher/files/us-gwburr/SCMandMIEC_overview_12Feb2013.pdf
www.arxiv.org/pdf/1903.05714.pdf
www.intel.com/content/dam/www/public/us/en/documents/solution-briefs/optane-persistent-memory-sap-hana-solution-brief.pdf
www.hardwareluxx.de/index.php/news/hardware/arbeitsspeicher/49187-preise-und-vergleiche-zu-optane-dc-persistent-memory.html
SAP HANA & Persistent Memory
In seinem Blog-Beitrag SAP HANA & Persistent Memory (blogs.sap.com/2018/12/03/sap-hana-persistent-memory/) führt der Product Manager für die SAP HANA Platform, Andreas Schuster, sinngemäß aus:
Mit dem Persistent Memory (PMEM) führt Intel eine zusätzliche Speicherschicht zwischen dem Byte-weise adressierbaren DRAM und den blockbasierten SSD-Speichergeräten ein. Die Eigenschaft „Persistent“ bedeutet, dass auch nach dem Neustart eines Servers, der PMEM verwendet, keine gespeicherten Informationen verloren gehen. Diese Speichertechnologie hat Intel mit den Optane DC Persistent Memory-Modulen auf den Markt gebracht. Die In-Memory-Datenbank SAP HANA wird bereits seit HANA 2.0 SPS 03 optimiert, um die Eigenschaften der PMEM-Technologie zu nutzen.
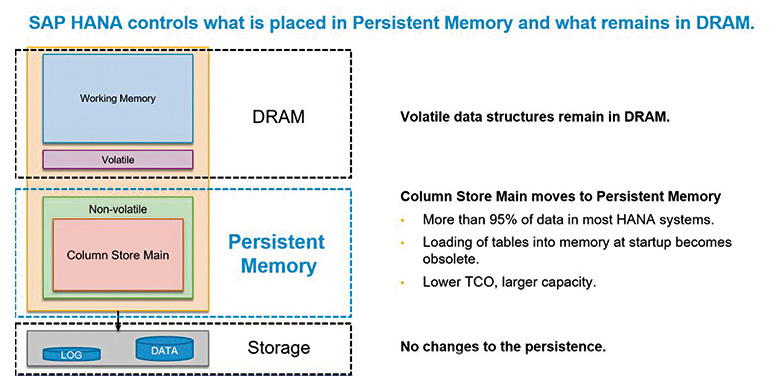
Die meisten Anwendungen verlassen sich bei der Speicherzuweisung und -verwaltung ausschließlich auf das Betriebssystem. Natürlich bekommt SAP HANA wie jede andere Anwendung auch Speicher aus dem Betriebssystem zugewiesen. Doch einmal zugewiesen, übernimmt die Applikation – also SAP HANA – ein viel höheres Maß an Kontrolle über das Speichermanagement. Der Grund dafür ist einfach: Dies ermöglicht einen wesentlich höheren Optimierungsgrad, denn die Optimierungen seitens der Anwendung beziehen sich auf die internen Datenstrukturen der Datenbank. Das ist besonders wichtig für eine In-Memory-Datenbank wie SAP HANA, denn sie „weiß“, welche Datenstrukturen am meisten vom persistenten Speicher profitieren. SAP HANA erkennt automatisch persistente Speicherhardware und passt sich selbst an, indem es diese Datenstrukturen automatisch auf persistenten Speicher legt, während alle anderen im DRAM verbleiben.
Das wird durch den „App Direct Modus“ des persistenten Speichers ermöglicht – eine von zwei Betriebsarten des persistenten Speichers, die Intel bekanntgegeben hat. Der „App Direct-Modus“ ermöglicht es Anwendungen, Daten dauerhaft im persistenten Speicher zu halten. Die zweite Betriebsart, der „Memory Modus“, wird von HANA nicht verwendet. Er bietet diese Datenpersistenz nicht, sondern ist darauf fokussiert, einen kostengünstigeren und/oder größeren Hauptspeicher zu unterstützen.
Im App Direct-Modus eignet sich der persistente Speicher besonders für nichtflüchtige Datenstrukturen. Angesichts dieser Eigenschaften ist der „Column Store Main“ ein ausgezeichneter Kandidat für die Platzierung im persistenten Speicher. Der „Column Store Main“ enthält in der Regel weit über 90 Prozent des Datenbestands der meisten HANA-Datenbanken und bietet somit viel Potenzial. Außerdem wird der „Column Store Main“ selten während des Delta-Merge-Vorgangs rekonstruiert. Üblicherweise erfolgt das erst nach dem Erreichen eines bestimmten Schwellenwerts bei Änderungen an der Datenbanktabelle. Für die meisten Tabellen kommt ein Delta-Merge nicht öfter als einmal am Tag vor.Rainer Huttenloher
{kind=link}